


Nous avons vu dans les articles précédents comment il était simple d’utiliser YOLO avec darknet (ici pour Yolo v4) et OpenCV. Maintenant il est temps d’aller un peu plus loin, mais avant de voir comment on pourra créer ses propres listes d’objets à détecter vous vous demandez peut être comment simplement réduire le nombre d’objets détectés par l’algorithme ? imaginez que vous ne vouliez détecter que les ordinateurs portables, ou que les livres et téléphones, etc. bref vous n’avez pas nécessairement besoin d’avoir tout le panel de détection que peut vous offrir un jeu de données tel que coco (avec 80 objets). Seul 1 ou quelques autres vous intéresse, comment faire alors ?
Modèles pré-entrainé et jeux de données
Rappelons tout d’abord que YOLO est un réseau de neurones, en tant que tel il peut fonctionner pour tout type de données. Bien souvent on va utiliser des modèles pré-entrainés pour des raisons évidentes de temps, de configuration et de ressources. Pourquoi refaire la roue ? Dans la plupart des cas on utilisera donc le modèle pré-entrainé COCO que l’on trouve facilement sur le site darknet (YOLO v4).
Il existe bien d’autres jeux de données tels que OpenImages, PASCAL VOC, etc. mais nous allons dans cet article voir comment réduire le nombre d’objets détecté de 80 (nombre de classes pré-entrainées avec COCO) à une seule.
Pour une liste assez complète des jeux de données, allez voir ici
Pour récupérer un modèle pré-entrainé avec YOLO, vous aurez besoin de télécharger 3 fichiers:
- Les poids pré-entrainés (*.weights) [Téléchargez ici la version 4, attention le fichier fait plus de 250 Mo]
- Le fichier de configuration du réseau (*.cfg) [Téléchargez ici le fichier en version 4]
- La liste des classes (coco.names) [Téléchargez ici]
Note: Nous verrons par la suite (articles suivants) comment créer notre modèle personnalisé avec YOLO.
Attention aussi de ne pas se tromper quand vous téléchargez vos fichier de bien se référer à la bonne version de YOLO (v2 vs v3 vs v4).
Modifier le modèle ?
Parfois quand on veut réduire le scope de détection (c’est à dire réduire le nombre de possibilité de détection d’objet) c’est pour soit accélérer la détection (par exemple pour de la détection temps réel sur un flux vidéo), soit pour juste réduire le nombre de cadre affichés et rendre donc plus lisible le résultat de la détection. On fait alors très vite l’association d’idée réduire le nombre d’objet équivaut a réduire le temps de travail et donc accélérer la détection.
C’est vrai, mais à une condition.
Reconstruire le modèle (et ça nous le verrons après) ! si on utilise un modèle pré-entrainé il faut bien se dire qu’il a entièrement été conçu pour les classes avec lesquelles il a été entrainé: réduire le nombre de classe détectée n’accélèrera donc pas son temps de traitement (il y a bien une astuce avec YOLO v3 mais a priori pas de solution pour YOLO v4).
Dans cet article nous allons donc nous pencher sur comment réduire le nombre de cadres (et donc d’objets) détectés tout en utilisant un modèle pré-entrainé (COCO), afin d’éviter cette boulimie de cadres multi couleurs sur nos images.
Préparation
Comme dans les articles précédents nous allons utiliser Python, darknet/yolo v4, OpenCV et l’environnement Google colab.
L’astuce que nous allons pratiquer est vraiment très simple est consiste :
- A modifier la liste des classes (Objets – labels) par défaut.
- A filtrer ensuite lors de l’affichage les cadres (objets) non voulus
L’algorithme va donc faire son travail et détecter les 80 objets pour lesquels il a été conçu, par contre nous ne filtrerons que ceux qui nous intéresse.
Modifions tout d’abord le fichier de classes : coco.names, et pour commencer le mieux est de créer une copie de l’original et le renommer en laptop.names par exemple si on ne veut détecter que les ordinateurs portables.
Si vous ouvrez ce fichiers, vous verrez une liste (par ligne) des 80 objets détectés par le modèle. Surtout ne supprimez pas toutes les lignes qui ne vous intéressent pas car l’index de la ligne a son importance. Le plus simple est de remplacer les classes par le même mot clé (qui ne correspond à aucun objet bien sur) afin de garder chaque rang de classe.
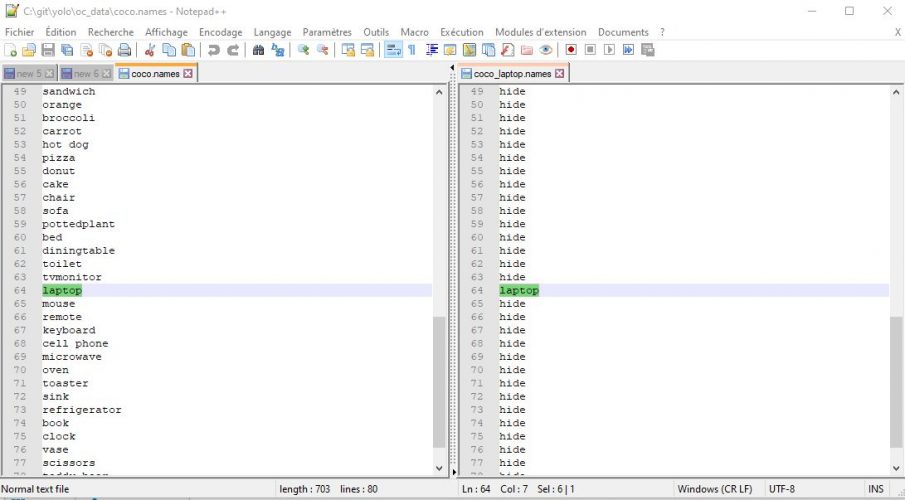
Dans l’exemple ci-dessus j’ai simplement remplacer toutes les noms de classe (excepté laptop) par le mot < hide >.
Traitement avec Google colab
Initialisation
Avant tout (et pour utiliser YOLO v4 dans Google colab), il faut mettre à jour OpenCV:
pip install --upgrade opencv-python
Puis initialiser l’environnement (comme nous l’avons vu dans les articles précédents):
import numpy as np import cv2 from google.colab.patches import cv2_imshow # colab does not support cv2.imshow() ROOT_COLAB = '/content/drive/MyDrive/Colab Notebooks/YOLO' YOLO_CONFIG = ROOT_COLAB + '/oc_data/' COCO_LABELS_FILE = YOLO_CONFIG + 'coco_laptop.names' YOLO_CONFIG_FILE = YOLO_CONFIG + 'yolov4.cfg' YOLO_WEIGHTS_FILE = YOLO_CONFIG + 'yolov4.weights' LABELS_FROM_FILE = False IMAGE_FILE = 'yoloimg3.jpg' IMAGE = cv2.imread(ROOT_COLAB + '/' + IMAGE_FILE) CONFIDENCE_MIN = 0.5
Notez bien qu’en ligne 7 on se réfère bien au fichier de classes (*.names) que nous avons modifié et pas celui par défaut.
Voici notre image:
# Little function to resize in keeping the format ratio
# Source: https://stackoverflow.com/questions/35180764/opencv-python-image-too-big-to-display
def ResizeWithAspectRatio(_image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
image = _image.copy()
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
return cv2.resize(image, dim, interpolation=inter)
cv2_imshow(ResizeWithAspectRatio(IMAGE, width=700))

Nous avons 2 ordinateurs portables (laptops) à détecter …
Détection des ordinateurs portables
Tout d’abord, si nous avons réduit le nombre d’objet plus haut nous n’avons pas réduit pour autant le nombre de lignes. On retrouve donc bien 80 objets concrêtement mais 79 seront les mêmes (hide).
with open(COCO_LABELS_FILE, 'rt') as f:
labels = f.read().rstrip('\n').split('\n')
len(labels)
80Lançons la détection :
(H, W) = IMAGE.shape[:2]
yolo = cv2.dnn.readNetFromDarknet(YOLO_CONFIG_FILE, YOLO_WEIGHTS_FILE)
yololayers = [yolo.getLayerNames()[i[0] - 1] for i in yolo.getUnconnectedOutLayers()]
blobimage = cv2.dnn.blobFromImage(IMAGE, 1 / 255.0, (416, 416), swapRB=True, crop=False)
yolo.setInput(blobimage)
layerOutputs = yolo.forward(yololayers)
boxes_detected = []
confidences_scores = []
labels_detected = []
# loop over each of the layer outputs
for output in layerOutputs:
# loop over each of the detections
for detection in output:
# extract the class ID and confidence (i.e., probability) of the current object detection
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
# Take only predictions with confidence more than CONFIDENCE_MIN thresold
if (confidence > CONFIDENCE_MIN and labels[classID] != "hide"):
# Bounding box
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# Use the center (x, y)-coordinates to derive the top and left corner of the bounding box
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# update our result list (detection)
boxes_detected.append([x, y, int(width), int(height)])
confidences_scores.append(float(confidence))
labels_detected.append(classID)
Appliquons ensuite l’algorithme de NMS comme nous l’avons vu dans l’article précédent:
final_boxes = cv2.dnn.NMSBoxes(boxes_detected, confidences_scores, 0.5, 0.5)
image = IMAGE.copy()
# loop through the final set of detections remaining after NMS and draw bounding box and write text
for max_valueid in final_boxes:
max_class_id = max_valueid[0]
# extract the bounding box coordinates
(x, y) = (boxes_detected[max_class_id][0], boxes_detected[max_class_id][1])
(w, h) = (boxes_detected[max_class_id][2], boxes_detected[max_class_id][3])
# draw a bounding box rectangle and label on the image
color = [255, 255, 0]
cv2.rectangle(image, (x, y), (x + w, y + h), [255, 255, 0], 3)
score = str(round(float(confidences_scores[max_class_id]) * 100, 1)) + "%"
text = "{}: {}".format(labels[labels_detected[max_class_id]], score)
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
cv2_imshow(ResizeWithAspectRatio(image, width=700))

Voilà la résultat, seuls les ordinateurs portables ont été détecté !
Certes nous avons un peu triché pour simplifié la détection. Nous l’avons fait afin de pouvoir pleinement réutiliser un modèle pré-entrainé. Dans les articles suivants nous verrons comment avec YOLO nous allons pouvoir créer notre propre modèle afin de détecter des objets qui ne sont pas proposé par des modèles pré-entrainés.
Les sources de cet article (le notebook colab) est téléchargeable ici
Lire la suite
Dans l’article suivant nous allons commencer à créer notre modèle personnalisé YOLO.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Bonjour Benoit, je viens de parcourir les 4 premiers chapitres, c’est très bien expliqué, très pédagogique, merci beaucoup, je vais attaquer la suite avec mon propre modèle.
A suivre.