

Modèle personnalisé
Dans cet article et les trois prochains de cette série nous allons créer notre modèle personnalisé avec YOLO. L’idée est de faire apprendre à YOLO la détection de nouveaux objets. Nous allons donc devoir entraîner YOLO (avec le réseau de neurones darknet que nous avons déjà vu précédemment). Mais qui dit entraîner un modèle dit respecter d’une part un certain nombre de pré-requis (techniques, configuration et matériels) et d’autres part de posséder un jeu de données pour pouvoir faire apprendre correctement notre modèle.
Voici donc notre liste de courses pour pouvoir entrainer un modèle avec YOLO:
- Google colab (sans quoi il vous faudra un ordinateur possédant un GPU)
- Un jeu de données assez conséquent (env. 500-1000 images minimum, pour ce tuto je vais prendre un échantillon de 300 images seulement … nous verrons bien le résultat !)
- De la patience ! car l’entrainement dure longtemps, pour ce tuto il a prit plus de 12 heures !
- Nous aurons besoin d’un logiciel pour labelliser nos images. Il existe aujourd’hui pas mal d’outils tels que KILI Technology qui sont très intéressants, surtout dés lors que l’on doit collaborer dans cette tâche vitale qu’est la labellisation. Dans le cadre de ce tuto j’utiliserai LabelImg que vous pouvez télécharger ici.
Jeux de données
Pour ce qui est du jeu de données, je vais aller en prendre un ou plutôt un morceau de jeu de données public. SI comme moi vous chercher un jeu de données libre d’accès et d’usage, allez piocher sur ce site : https://paperswithcode.com/datasets
Pour ce tuto nous allons entraîner YOLO à détecter des documents de toute sorte. Notre entrainement ne portera donc que sur une seule classe et nous entraînerons YOLO avec 300 images. Vous trouverez les images que j’ai utilisées dans Github.
Pour résumer:
- 1 seule classe (document)
- Entrainement sur 300 images (de tailles et format différentes)
Labellisation
Maintenant que nous avons les images, il va falloir préciser où dans l’image se situent la ou les documents que nous allons devoir ensuite détecter. C’est ce que l’on appelle l’étape de labellisation. Malheureusement ce n’est pas l’étape la plus sympathique car vous allez vous en rendre compte qu’elle est longue et rébarbative ! Le but est très simple pour chacune des photos/images (donc 300 ici) nous allons devoir déterminer et annoter les cadres qui contiennent un document (ou plusieurs !).
Pas le choix, il faut faire ce travail sur chaque photo … et manuellement !
Pour faire simple je vous propose de télécharger et installer le logiciel gratuit LabelImg. Une fois installé vous pourrez ouvrir une image ou un répertoire contenant toutes vos images et commencer cette tâche fastidieuse mais si importante de labellisation.
LabelImg
Le logiciel LabelImg est un logiciel très simple d’utilisation, même si il n’est pas forcément adapté dans un contexte professionnel, il va nous aider ici a créer:
- Un fichier txt par image contenant les coordonnées de chaque cadre comprenant le ou les objets à détecter.
- Le fichier contenant les libellés ou classes. Dans notre cas nous ne créerons qu’une seule classe: document.
Ouvrons le logiciel:
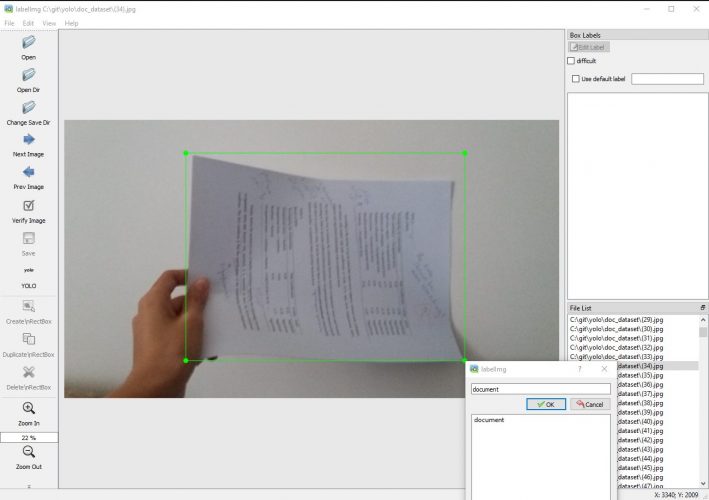
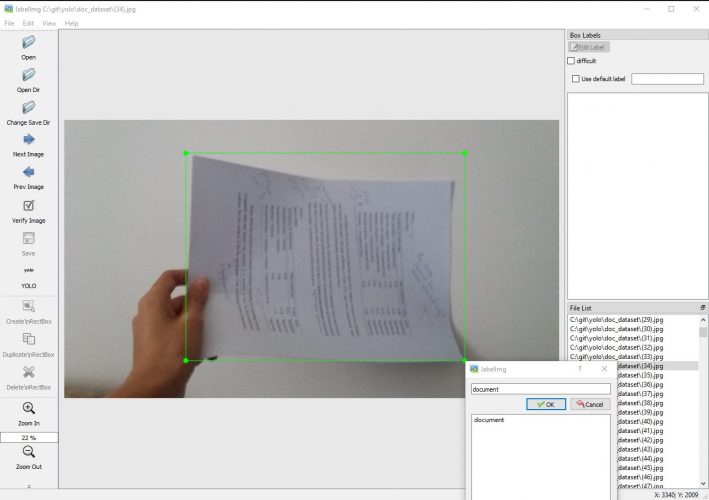
Une fois de plus ce logiciel est vraiment très simple et se présente de la sorte:
- Un panneau à gauche dans lequel on trouve les fonctions.
- Par défault le format PASCAL/VOC est sélectionné, changez-le tout de suite pour utiliser le format YOLO.
- Je vous suggère aussi de travailler sur un répertoire dans lequel vous avez placé toutes vos images et ainsi choisir l’option Open Dir, puis pointer dessus. Une fois sélectionné remarquez le volet en bas à droite qui va lister toutes vos images.
- Dans le menu:
- Sélectionnez dans View, l’option Auto Save Mode
- Puis « Single Class Mode » (car nous n’aurons que la classe document)
Maintenant on peut commencer à parcourir image après image et sélectionner ce que nous trouvons comme documents. Une fois que vous avez une nouvelle image, appuyez sur la touche « w », c’est un raccourci qui vous permet de directement tracer un cadre et vous fait gagner du temps.
Attention, une fois de plus LabelImg est un petit utilitaire (bien pratique tout de même) mais dont il faut connaître quels trucs comme:
- Si l’image est trop grande par rapport au cadre, vous ne pourrez pas créer de boite autour d’un objet qui est sur les bords. Dans ce cas, zoomez.
- Si vous fermez LabelImg en cours de votre tâche de labellisation, il vous faudra ressaisir le nom du label (le logiciel n’est pas capable de le retrouver via le fichier classes.txt). Veillez à resaisir exactement le même label sans quoi vous aurez un doublon dans votre fichier classes.txt
- Etc.
Résultat
Une fois que vous aurez passé en revue vos images (300 dans notre cas ici), vous devez avoir:
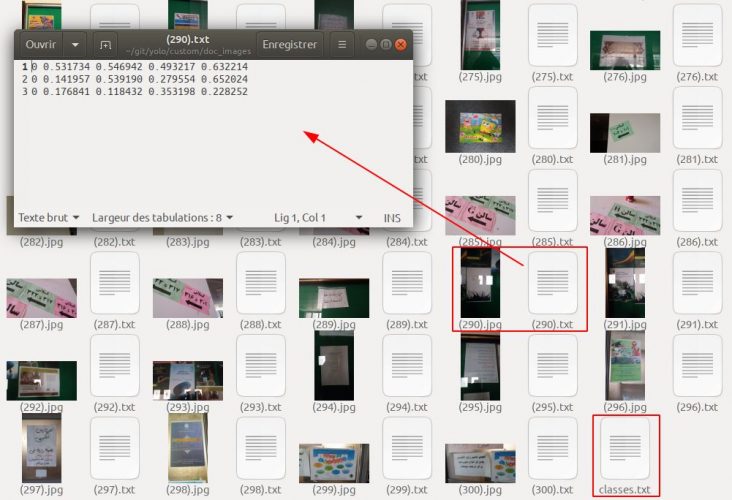
- Dans le même répertoire que vos images, un fichier txt qui porte le même nom que l’image et qui contient les coordonnées du ou des rectangles contenant les objets. Voici un exemple pour une image contenant 4 documents :
0 0.827519 0.587640 0.344961 0.804048
0 0.374273 0.542205 0.557171 0.645995
0 0.602713 0.080319 0.452519 0.159776
0 0.208697 0.110680 0.339874 0.220500- un fichier classes.txt, qui ne contient qu’une seule ligne:
documentConclusion
Vos données sont maintenant prêtes à être entraînées par le réseau YOLO darknet. Nous allons voir dans le chapitre suivant comment configurer le réseau pour qu’il puisse prendre en charge l’entrainement de ces nouveaux objets.
Lire la suite
Dans l’article suivant nous allons configurer le réseau darknet pour pouvoir l’entrainer avec colab.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Bonjour,
Merci pour cette série sur Yolo.
Vos explications sont très pertinentes.
J’attends avec impatience les 2 prochains chapitres.
Bon courage
A.M