
Dans le dernier article de la série de traitement d’image nous avons abordé les réseaux de neurones à convolution. Nous en avons même créé un, mais il faut le reconnaître très simple. Le soucis dés lors que l’on veut avoir de bon résultats c’est qu’il faut déjà beaucoup d’images mais aussi beaucoup de ressources car très vite on doit empiler un bon nombre de couches dans notre réseau de neurones profond afin d’avoir une précision correcte.
Bref, la question du temps, des ressources mais aussi des choix d’hyperparamètres du réseau de neurones peuvent devenir bloquant pour nombre de projets.
Et si on réutilisait un morceau de réseau de neurones existant et pré-entrainé ?
C’est exactement l’objectif que l’on cherche à réaliser avec le Transfer Learning! et pour ce faire il y a beaucoup de réseau de neurones qui sont d’ores et déjà disponible. Nous allons commencer dans cet article par l’un des plus connu le VGG.
Qu’est-ce que VGG-16 ?
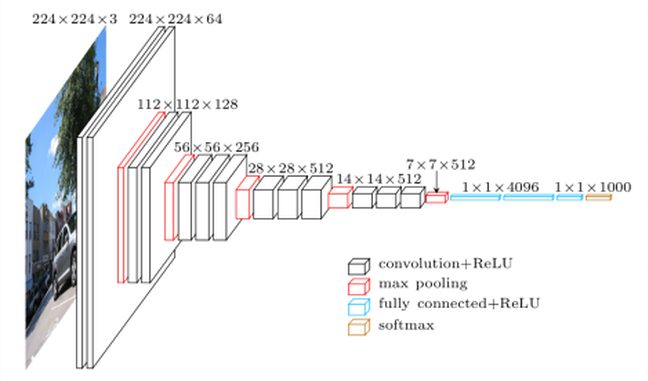
VGG16 est un modèle de réseau de neurones à convolution conçu par K. Simonyan et A. Zisserman. On retrouve les détails d’implémentation dans le document «Very Deep Convolutional Networks for Large-Scale Image Recognition». Ce modèle atteint une précision de test de 92,7% dans ImageNet, qui qui regroupe plus de 14 millions d’images appartenant à 1000 classes. Pourquoi vgg-16 et bien tout simplement parceque ce réseau de neurones comprend 16 couches profondes :
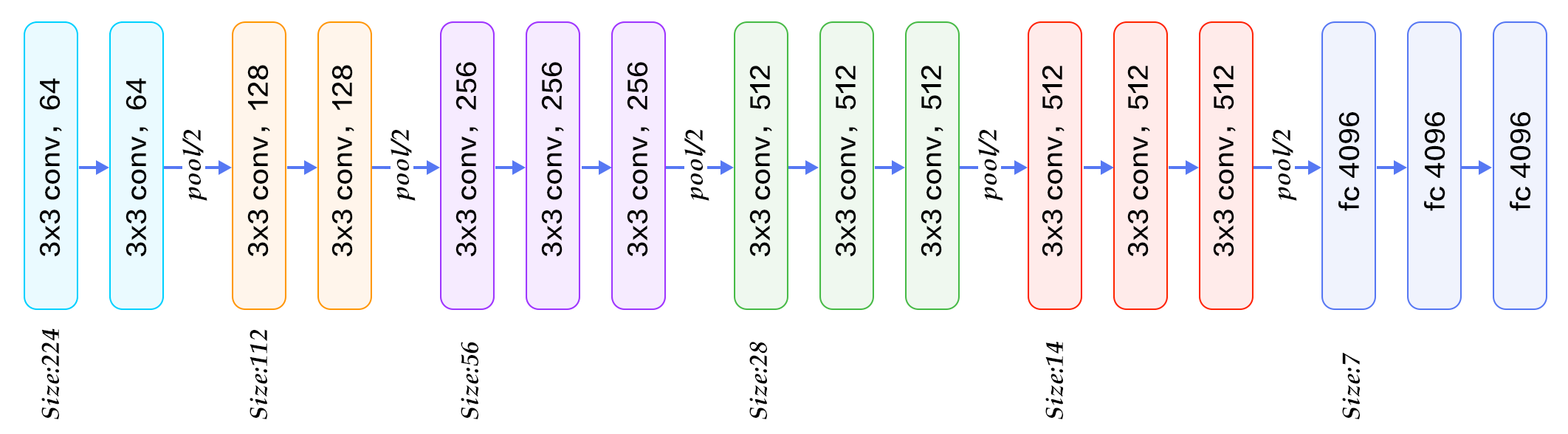
Alors bien sur, vous pourriez créer par vous même ce réseau, puis trouver les meilleurs hyperparamètres pour enfin l’entrainer. Mais cela vous prendrait beaucoup de temps et de ressources … alors pourquoi ne pas utiliser tous les paramètres de ce modèle et voir comment compléter ce réseau en y ajoutant des couches personnalisées ?
C’est exactement ce que nous allons faire dans cet article, et nous allons le faire bien sur avec des classes pour lesquelles VGG n’a pas été entrainé. Dingue n’est-ce pas ? c’est une peu la magie des réseaux de neurones convolutifs. On va pouvoir en fait réutiliser les mécanismes de détection de forme (feature map) qui ont été réalisé par le VGG mais pour détecter d’autres formes.
VGG & TensorFlow
Bonne nouvelle, Tensorflow fournit en standard le modèle VGG-16 et rend donc le Transfer Learning très simple.
En fait il fournit en standard d’autres modèles pré-entrainés tels que :
- VGG16
- VGG19
- ResNet50
- Inception V3
- Xception
Vous allez voir que du coup la réutilisation de ces modèles est d’une simplicité enfantine 🙂
Réalisons un détecteur de fruit !
Pour tester notre modèle personnalisé (Transfer Learning) VGG-16 nous allons utiliser un dataset composé d’images de fruits (131 types de fruits pour être exact). Vous pouvez trouver ce dataset sur Kaggle à l’adresse suivante : https://www.kaggle.com/moltean/fruits
Attention si vous voulez me suivre pas à pas et créer votre propre réseau de neurones, sachez qu’il vous faudra de la puissance (GPU/TPU). Je vous suggère donc de faire comme moi et de créer un notebook dans Kaggle.
Vous pouvez regarder le miens ici : https://www.kaggle.com/shiftbc/fruit-and-vgg
Présentation du dataset
Le dataset est structuré par répertoire (et vous verrez que cette structure ne doit rien au hasard) :
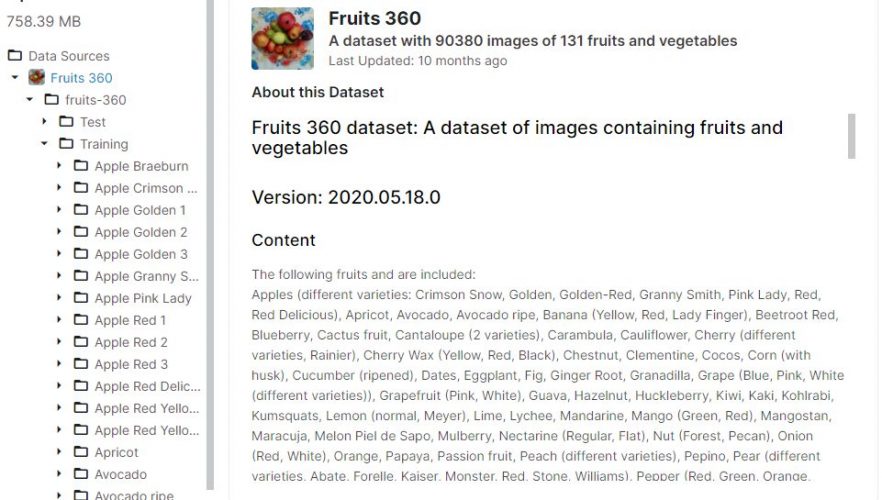
Nous avons deux jeux de données : Entrainement (Training) et Test (Test). Dans chacun de ces répertoires on trouve des sous-répertoire (étiquettes) dans lesquels on a les photos des différents fruits.
Voici quelques informations supplémentaires qui peuvent être utiles par la suite :
- Nombre d’image totales: 90483
- Un fruit par image
- Jeu d’entrainement: 67703 images
- Jeu de test: 19543 images
- Nombre de classes/fruits: 131
- Taille des images: 100×100 pixels
Démarrage
Commençons par importer les librairies nécessaires :
import numpy as np import pandas as pd from glob import glob from keras.layers import Input, Lambda, Dense, Flatten from keras.models import Model from keras.applications.vgg16 import VGG16 from keras.applications.vgg16 import preprocess_input from keras.preprocessing import image from keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.callbacks import EarlyStopping import numpy as np import matplotlib.pyplot as plt from skimage.io import imread, imshow
Et regardons une image :
image = imread("/content/drive/MyDrive/Colab Notebooks/fruits-360/Training/Apple Braeburn/0_100.jpg")
plt.imshow(image)
Parfait nous avons une belle pomme en couleur (RGB).
image.shape
(100, 100, 3)La taille des images est bien de 100 par 100 pixels.
Data Augmentation avec Tensorflow
90483 images c’est bien, mais plus serait encore mieux. Je vais profiter de cet article pour faire ce que l’on appelle de l’augmentation de données. Le principe est très simple, l’idée est de décliner une image en faisant des décalages, rotations, zooms afin de la dupliquer en plusieurs exemplaires. A partir d’une image on peut donc avoir x nouvelles images et donc améliorer l’apprentissage de notre modèle par cette méthode.
Avec TensorFlow nous utiliserons ce que l’on appelle des Generator. il en existe plusieurs mais ici nous allons utiliser le Générateur d’image ImageDataGenerator() qui va faire tout ce travail de duplication pour nous et de manière automatique.
Pour commencer on configure la manière dont on va créer les déclinaisons d’image avec la fonction ImageDataGenerator()
Ensuite on va utiliser et appliquer ce Generator a nos deux jeux de données (Training et Test)
src_path_train = "/content/drive/MyDrive/Colab Notebooks/fruits-360/Training"
src_path_test = "/content/drive/MyDrive/Colab Notebooks/fruits-360/Test"
batch_size = 32
image_gen = ImageDataGenerator(
rescale=1 / 255.0,
rotation_range=20,
zoom_range=0.05,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05,
horizontal_flip=True,
fill_mode="nearest",
validation_split=0.20)
# create generators
train_generator = image_gen.flow_from_directory(
src_path_train,
target_size=IMSIZE,
shuffle=True,
batch_size=batch_size,
)
test_generator = image_gen.flow_from_directory(
src_path_test,
target_size=IMSIZE,
shuffle=True,
batch_size=batch_size,
)
Found 67703 images belonging to 131 classes.
Found 19543 images belonging to 131 classes.Voilà c’est terminé ! simple n’est-ce pas ?
Création du modèle
Nous allons maitenant créer le modèle à partir de VGG-16.
3 choses minimum à retenir ici :
- L’utilisation de la classe VGG16 fournie par TensorFlow (ici on utilise les poids imagenet), include_top précise qu’on prend tout le modèle excepté la dernière couche
- On tag les couches du réseau de neurones afin de ne pas écraser l’apprentissage déjà récupéré (layer.trainable = False)
- L’ajout d’une nouvelle couche Dense à la fin (on pourrait en ajouter d’autres d’ailleurs), c’est cette couche qui fera le choix de tel ou tel fruit.
NBCLASSES = 131
train_image_files = glob(src_path_train + '/*/*.jp*g')
test_image_files = glob(src_path_test + '/*/*.jp*g')
def create_model():
vgg = VGG16(input_shape=IMSIZE + [3], weights='imagenet', include_top=False)
# Freeze existing VGG already trained weights
for layer in vgg.layers:
layer.trainable = False
# get the VGG output
out = vgg.output
# Add new dense layer at the end
x = Flatten()(out)
x = Dense(NBCLASSES, activation='softmax')(x)
model = Model(inputs=vgg.input, outputs=x)
model.compile(loss="binary_crossentropy",
optimizer="adam",
metrics=['accuracy'])
model.summary()
return model
mymodel = create_model()
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 100, 100, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 100, 100, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 100, 100, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 50, 50, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 50, 50, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 50, 50, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 25, 25, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 25, 25, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 25, 25, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 25, 25, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 12, 12, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 12, 12, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 12, 12, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 12, 12, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 6, 6, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 6, 6, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 6, 6, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 6, 6, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 3, 3, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 4608) 0
_________________________________________________________________
dense_1 (Dense) (None, 131) 603779
=================================================================
Total params: 15,318,467
Trainable params: 603,779
Non-trainable params: 14,714,688
_________________________________________________________________On retrouve toutes les couches du VGG-16 en amont et la couche que l’on a ajouté (Dense / 131) à la fin. Notez aussi le nombre de paramètres pré-entrainés (14,714,688) que l’on va réutiliser.
Entraînement
L’entraînement va prendre beaucoup mais alors beaucoup de temps si vous n’avez pas de GPU sous la main, utilisez colab ou kaggle si vous n’en n’avez pas à disposition.
epochs = 30 early_stop = EarlyStopping(monitor='val_loss',patience=2) mymodel.fit( train_generator, validation_data=test_generator, epochs=epochs, steps_per_epoch=len(train_image_files) // batch_size, validation_steps=len(test_image_files) // batch_size, callbacks=[early_stop] )
Epoch 1/10
2115/2115 [==============================] - 647s 304ms/step - loss: 0.0269 - accuracy: 0.6334 - val_loss: 0.0085 - val_accuracy: 0.8802
Epoch 2/10
2115/2115 [==============================] - 289s 136ms/step - loss: 0.0037 - accuracy: 0.9787 - val_loss: 0.0055 - val_accuracy: 0.9295
Epoch 3/10
2115/2115 [==============================] - 290s 137ms/step - loss: 0.0018 - accuracy: 0.9923 - val_loss: 0.0047 - val_accuracy: 0.9391
Epoch 4/10
2115/2115 [==============================] - 296s 140ms/step - loss: 0.0012 - accuracy: 0.9959 - val_loss: 0.0043 - val_accuracy: 0.9522
Epoch 5/10
2115/2115 [==============================] - 298s 141ms/step - loss: 8.8540e-04 - accuracy: 0.9967 - val_loss: 0.0040 - val_accuracy: 0.9524
Epoch 6/10
2115/2115 [==============================] - 298s 141ms/step - loss: 6.6982e-04 - accuracy: 0.9985 - val_loss: 0.0037 - val_accuracy: 0.9600
Epoch 7/10
2115/2115 [==============================] - 299s 142ms/step - loss: 5.5506e-04 - accuracy: 0.9984 - val_loss: 0.0035 - val_accuracy: 0.9613
Epoch 8/10
2115/2115 [==============================] - 353s 167ms/step - loss: 4.5906e-04 - accuracy: 0.9988 - val_loss: 0.0037 - val_accuracy: 0.9599
Epoch 9/10
2115/2115 [==============================] - 295s 139ms/step - loss: 3.9744e-04 - accuracy: 0.9987 - val_loss: 0.0033 - val_accuracy: 0.9680
Epoch 10/10
2115/2115 [==============================] - 296s 140ms/step - loss: 3.4436e-04 - accuracy: 0.9993 - val_loss: 0.0035 - val_accuracy: 0.9671Evaluation rapide
score = mymodel.evaluate_generator(test_generator)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
Test loss: 0.003505550790578127
Test accuracy: 0.9680007100105286Avec une précision de 97% on peut dire que le modèle a plutôt très bien fait son travail … et vous avez vu ? en si peu de lignes de code Python/Tensorflow, tout ça grâce au « Transfer Learning »
Une fois de plus je vous invite à regarder mon notebook sur Kaggle : https://www.kaggle.com/shiftbc/fruit-and-vgg
Essayez de rajouter des couches, de changer des paramètres, etc.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Bonjour,
Merci pour cet article très clair!
J’ai néanmoins une question. Lorsque vous testez votre modèle à la fin, ne devriez-vous pas le faire sur des données différentes de celles que vous avez utilisées lors de l’évaluation ? Ou autrement dit, les données de validation que vous utilisez dans le fit (‘validation data’) ne devraient-elles pas provenir des données d’entraînement (par exemple en faisant en sorte que 20% des données d’entraînement sont réservées à la validation) ? En effet, il me semble que si l’on ne fait pas cela, et que l’on fait ce que vous faites, il y a en quelque sorte une fuite de données au moment du fit. Ainsi, cela résulte en un très bon score de test à la fin, mais je pense que si l’on teste votre modèle sur de nouvelles données qu’il n’a jamais rencontrées, le score risque d’être moins bon.
Merci d’avance.
Bonjour,
C’est une excellent remarque, et surtout totalement justifiée. Vous avez raison, pour bien faire il ne faut pas réutiliser des données utilisées pour l’entrainement. J’avoue, pour cet exemple j’ai été un peu fainéant et n’ai pas récupéré de données toute neuve, l’idée était de montrer comment réutiliser le modèle 😉
NB: j’ai d’ailleurs fait un petit billet sur le sujet : https://www.datacorner.fr/dataset-prepare/