

Pour faire suite à mon article sur la gestion des chaînes de caractères, voici un premier volet qui va nous permettre d’avoir une approche progressive du traitement de ce type de données. Loin de toute approche sémantique (qui fera l’objet d’un post ultérieur) nous allons aborder ici la technique des sacs de mots. Cet technique, aussi appelée « bag of words » est une première approche simple et bien plus efficace qu’il n’y parait.
Nous allons voir tout d’abord les principes globaux de cette technique puis nous verrons comment avec scikit-learn (Python) nous pouvons mettre en place un cas pratique et voir son exécution.
Le principe du sac de mots
En fin de compte le principe du sac de mots est plutôt simple. On peut dire qu’il ressemble même à celui de l’encodage one-hot que nous avons vu dans un précédent article. Son principe se résume en 3 phases :
- La décomposition des mots. On appelle cela aussi la tokenisation.
- La constitution d’un dictionnaire global qui sera en fait le vocabulaire.
- L’encodage des chaînes de caractère par rapport au vocabulaire constitué précédemment.
Voici un schéma de principe
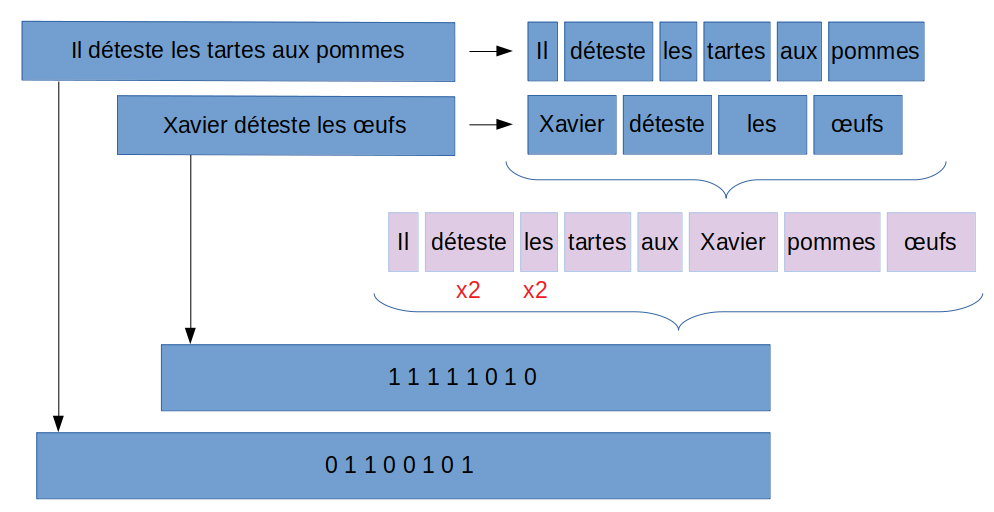
La tokenisation
La tokenisation est une étape simple mais indispensable. Le principe est simple il faut découper la ou les phrases en phonèmes ou mots. Bien sur on pense tout de suite à découper avec les espaces, mais nous n’oublierons pas non plus les éléments de ponctuation. Heureusement Scikit-Learn nous aide dans cette étape avec ses fonctions de tokenisation prête à l’emploi :
CountVectorizer() et TfidfVectorizer()
La création du vocabulaire
Il est évident qu’on ne va pas traiter une seule phrase ! on va devoir en traiter un grand nombre, et donc nous allons constituer une sorte de dictionnaire (ou vocabulaire) qui va consolider tous les mots que l’on a tokenisé. Cf. schéma ci-dessus.
Ce dictionnaire (vocabulaire) nous permettra par la suite de réaliser l’encodage nécessaire pour « numériser » nos phrases. En fait et pour résumer, cette étape nous permet de créer notre sac de mots. Nous aurons donc à la fin de cette étape tous les mots (uniques) qui constituent les phrases de notre jeu de données. Attention à chaque mot sera aussi octroyé un ordre, cet ordre est très important pour l’étape d’encodage qui suit.
L’encodage
Voilà l’étape qui va transformer nos mots en nombre. Une fois de plus l’idée est simple, à partir d’une phrase de votre jeu de données, vous faites correspondre au vocabulaire précédemment constitué. Attention bien sur à bien reprendre l’ordre établit dans l’étape précédente !
Ainsi pour chaque nouvelle phrase, il faut la tokeniser (même méthode que pour la constitution du vocabulaire) et y confronter ensuite chaque mot. Si le mot de la phrase existe dans le vocabulaire, il suffit alors de mettre un 1 l’emplacement (ordre) du mot dans le vocabulaire.
Mise en oeuvre avec Scikit-Learn
Pour exemple nous allons prendre le jeu de données que nous avions scrappé ici (jeux vidéos).
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
T = pd.read_csv("../webscraping/meilleursjeuvideo.csv")
cv = CountVectorizer()
texts = T["Description"].fillna("NA")
cv.fit(texts)
La fonction CountVectorizer() est une fonction magique qui va découper (via expression régulière) la phrase. Ici nous allons créer un vocabulaire à partir de la colonne Description et « tokenizer » toutes les colonnes.
cv = CountVectorizer()
texts = T["Description"].fillna("NA")
cv.fit(texts)
print ("Taille: {}", len (cv.vocabulary_))
print ("Contenu: {}", cv.vocabulary_)
Voilà le vocabulaire automatiquement constitué par Scikit-Learn (on le récupère via vocabulary_) :
Taille: {} 2976
Contenu: {} {'dans': 681, 'ce': 435, 'nouvel': 1793, 'épisode': 2944, 'de': 688, 'god': 1197, 'of': 1827, 'war': 2874, 'le': 1480, 'héros': 1303, 'évoluera': 2970, 'un': 2755, 'monde': 1676, 'aux': 273, 'inspirations': 1357, 'nordiques': 1784, 'très': 2731, 'forestier': 1118, 'et': 1001, 'montagneux': 1683, 'beat': 332, 'them': 2654, 'all': 122, 'enfant': 938, 'accompagnera': 55, 'principal': 2080, 'pouvant': 2056, 'apprendre': 184, 'des': 710, 'actions': 71, 'du': 806, 'joueur': 1420, 'même': 1741, 'gagner': 1159, 'expérience': 1030, 'the': 2652, 'legend': 1486, 'zelda': 2903, 'breath': 381, 'wild': 2882, 'est': 1000, ..., 'apparaît': 177, 'tribu': 2715, 'wario': 2875, 'land': 1471, 'pyramide': 2157, 'peuplant': 1960}Vous remarquerez que c’est une liste constitué de mots et de nombres. Ces nombres ce sont les ordres d’encodage que nous avons mentionné plus haut, tout simplement.
Vous remarquerez aussi que le vocabulaire est constitué de 2976 mots. Cela signifie que les phrases qui constituent la colonne Description contiennent 2976 mots distincts.
Maintenant il nous faut créer la représentation des données elles-mêmes, pour cela on doit appeler la fonction transform():
bow = cv.transform(texts)
print ("Sac de mots: {}", bow)
sdm = bow.toarray()
sdm.shape
print(sdm)
Le résultat est une matrice (200, 2976) car nous avons 200 lignes et 2976 nouvelles colonnes.
array([[0, 0, 0, ..., 0, 0, 0],
[0, 1, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 1],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])Limiter la taille du vocabulaire
Si vous jetez un coup d’oeil au vocabulaire vous remarquerez que bon nombre de mots sont inutiles. On parle bien sur des mots de liaisons ou autres nombres qui n’apporterons pas vraiment de valeurs par la suite. Par ailleurs le nombre de colonnes avec la technique des sac de mots risque de croitre de manière impressionnante, il faut trouver un moyen de les limiter.
Une bonne méthode consiste donc à retirer du vocabulaire les mots inutiles. Pour cela on a au minimum 2 approches :
- Limiter la création du vocabulaire via le nombre d’occurence
- Utiliser les stop words
Limitation via le nombre d’occurrence
Par défaut quand nous avons créé notre vocabulaire à partir de jeux de données nous avons ajouté une entrée dés lors qu’il apparaissait au moins 2 fois. Nous pouvons simplement augmenter ce paramètre ce qui aura pour effet de limiter le nombre d’entrée dans le vocabulaire et donc de donner plus d’importance aux mots qui sont utilisés plusieurs fois.
Avec scikit-Learn il suffit d’utiliser le paramètre min_df comme suit :
cv = CountVectorizer(min_df=4).fit(texts)
print ("Taille: {}", len (cv.vocabulary_))
print ("Contenu: {}", cv.vocabulary_)
La taille du vocabulaire alors diminue considérablement : Taille: {} 379
Les stop Words
Mais que sont les Stop Words ?Tout simplement une liste de mots explicites à retirer du vocabulaire.
Scikit-Learn propose une liste de mots prédéfinie dans son API mais malheureusement qu’en Anglais, pour les autres langues il faudra créer sa propre liste.
Bien sur on peut partir de zéro et créer son propre fichier excel. On peut aussi partir d’une liste existante. Pour le Français, un bon point de départ est sur le site https://www.ranks.nl/stopwords/french. Il suffit de copier cette liste via le site ou pourquoi pas aussi de la scrapper ! Bref, je l’ai fait pour vous et n’hésitez pas à reprendre la liste ici (Github).
Ensuite rien de plus simple,
stopwordFR = pd.read_csv("stopwords_FR.csv")
cv = CountVectorizer(min_df=4, stop_words=stopwordFR['MOT'].tolist()).fit(texts)
print ("Taille: {}", len (cv.vocabulary_))
print ("Contenu: {}", cv.vocabulary_)
La taille diminue encore : Taille: {} 321
Et voilà, maintenant à la place de phrases vous avez récupéré des données numériques bien plus utilisables que des informations textuelles.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Bonjour,
Merci pour l’article enrichissant.
Juste une remarque dans la représentation du bag of words (les 2 flèches des représentations vectorielles de 2 phrases sont inversées)
KHENISSI,
En effet tu as totalement raison, merci pour cette précision/correction 🙂