

Dés lors que l’on analyse des données il est important (particulièrement si vous faites du Machine Learning) de détecter si vos variables (features) sont liées. Dans certains cas c’est évident (comme par exemple le lien de dépendance dans une hiérarchie) mais bien souvent ces liens ou corrélations sont presque invisible. Il va falloir détecter et mesurer donc ces liens potentiels. heureusement des outils et techniques existent, parcourons les ensemble.
Un peu de théorie
Pour reprendre la définition de Wikipédia que je trouve plutôt bien trouvée :
« En probabilités et en statistique, la corrélation entre plusieurs variables aléatoires ou statistiques est une notion de liaison qui contredit leur indépendance. «
L’objectif va donc consister à mesurer la puissance du lien qu’il y a entre deux (ou plusieurs) variables. Or ce lien peut être plus ou moins complexe. On pense tout d’abord à un lien de type linéaire … et par extension on va vite se tourner vers la régression linéaire pour trouver ce lien.
Lien linéaire
Naturellement donc nous allons évaluer la relation linéaire entre deux variables continues : c’est la corrélation de Pearson.
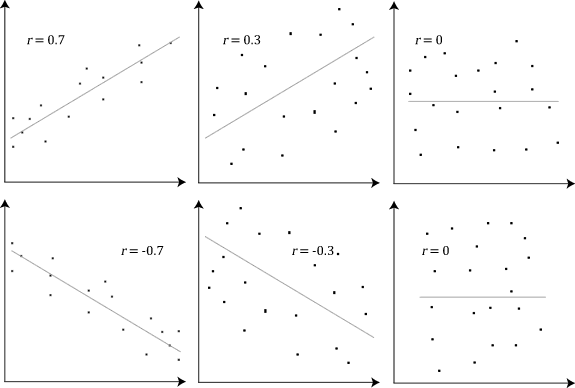
Les graphes ci-dessous montrent des coefficients de Pearson (r) qui montrent une corrélation positive (r>0), négative (r<0) ou l’absence de corrélation (r=0).
Lien non linéaire
Malheureusement toutes les relations de dépendances ne sont pas forcément linéaire, et donc il va falloir pousser plus loin les régressions (polynomiale, etc.). Nous allons donc nous tourner vers la corrélation de Spearman (rho) qui évalue la relation monotone entre deux variables. Dans une relation monotone, les variables ont tendance à changer ensemble, mais pas nécessairement à un taux régulier.
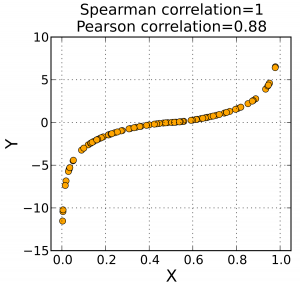
Reprenons une fois de plus la définition de Wikipédia :
On étudie la corrélation de Spearman quand deux variables statistiques semblent corrélées sans que la relation entre les deux variables soit de type affine. Elle consiste à trouver un coefficient de corrélation, non pas entre les valeurs prises par les deux variables mais entre les rangs de ces valeurs. Elle estime à quel point la relation entre deux variables peut être décrite par une fonction monotone.
Une dernière mesure (Tau de Kendall) permet de mesurer l’association entre deux variables. Plus spécifiquement, le tau de Kendall mesure la corrélation de rang entre deux variables.
Quelques différences quand même en ces deux mesures (utilisées dans la pratique pour des corrélations non linéaires):
- Tau de Kendall: renvoie des valeurs généralement inférieures à la corrélation rho de Spearman. Les calculs sont basés sur des paires concordantes et discordantes. Cette méthode est insensible à l’erreur. Les valeurs sont plus précises avec des échantillons plus petits.
- Rho de Spearman: donne des valeurs généralement plus grandes que le Tau de Kendall. Les calculs sont basés sur les déviations. il est beaucoup plus sensible aux erreurs et aux divergences dans les données (outliers).
Un peu de pratique avec Orange
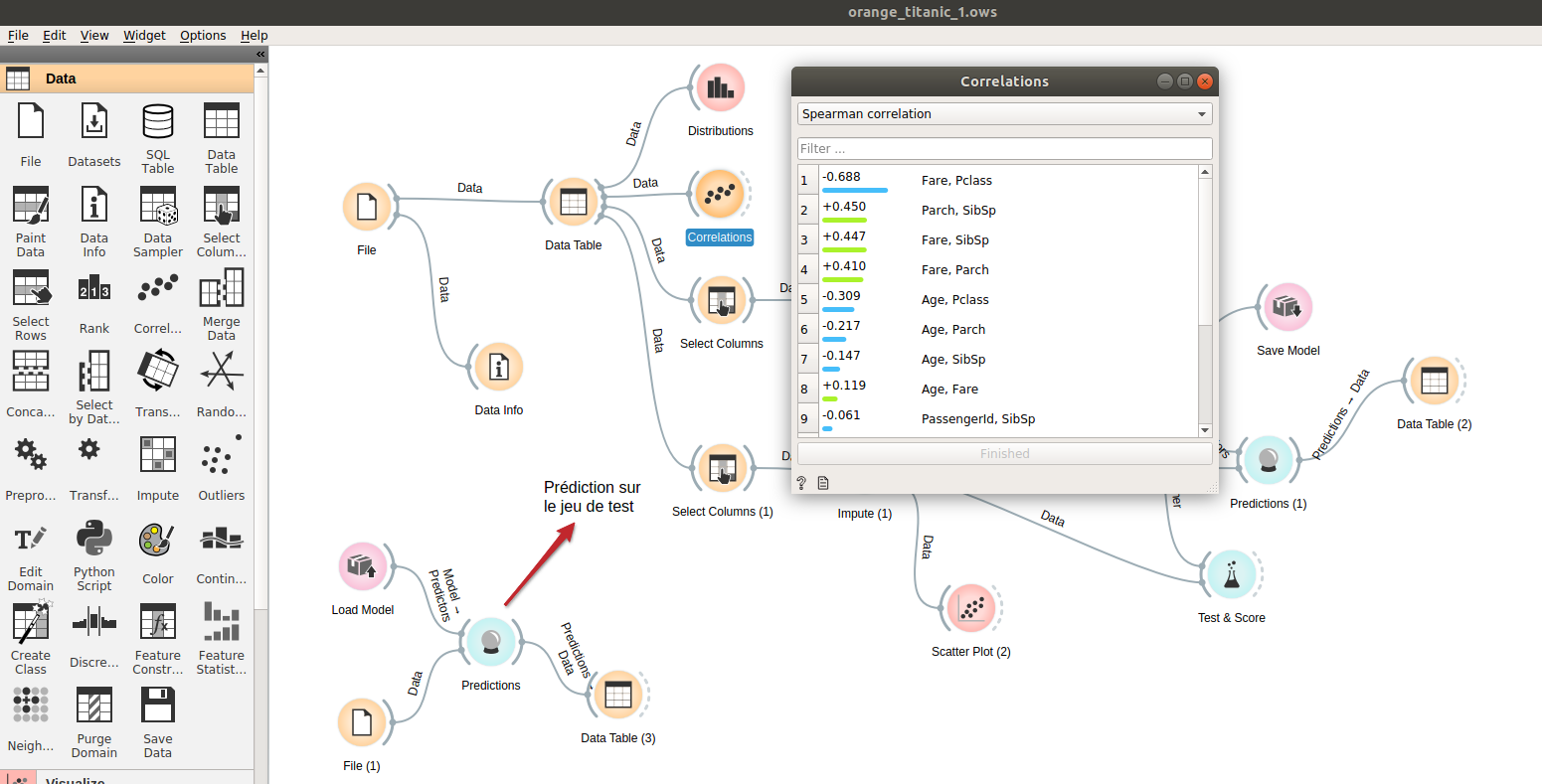
Avec Orange, rien de plus simple ! Utilisez le widget Correlation (groupe Data), et connectez le à une source de données comme ci-dessous. Vous pourrez consulter en quelques clics les coefficients de Pearson et Spearman (et non pas Kendall) :
Et avec Python !
En utilisant Python ce n’est guère plus complexe car le calcul de ces coefficients est inclus dans la librairie Pandas.
Prenons un exemple simple :
import pandas as pd import numpy as np from matplotlib import pyplot k = pd.DataFrame() k['X'] = np.arange(5)+3 k['Y'] = [1, 3, 4, 8, 12] pyplot.scatter(k['X'], k['Y'], s = 150, c = 'red', marker = '*', edgecolors = 'blue')
Voyons la distribution avec matplotlib :

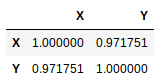
Un simple appel à la méthode corr() de l’objet Dataframe vous fournit la matrice de corrélation entre ces deux variables :
k.corr(method='pearson')
Pour demander un autre type de coefficient (Spearman, Kendall, ou personnalisé), il suffit de changer le parametre méthode comme suit :
k.corr(method='spearman') k.corr(method='kendall')
Pour calculer les corrélations sur un ensemble de colonnes, ce n’est pas plus compliqué, il suffit de passer tout le DataFrame
titanic = pd.read_csv("../datasources/titanic/train.csv")
data = titanic.drop(['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1)
data.corr(method='spearman')
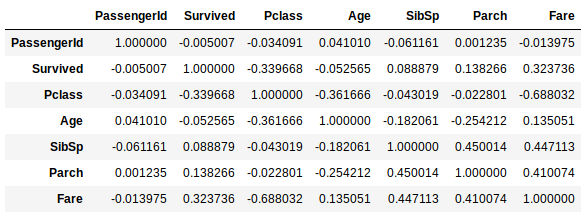
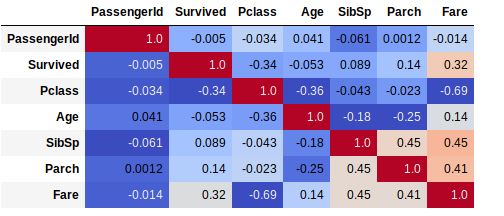
Avec une grille de chaleur, cela rendra le résultat plus visible et interpretable :
data.corr(method='spearman').style.format("{:.2}").background_gradient(cmap=pyplot.get_cmap('coolwarm'))
# Cf. https://matplotlib.org/examples/color/colormaps_reference.html pour les codes couleurs
Voilà maintenant vous savez ce qu’il vous reste à faire dés lors que vous entrerez dans la phase d’analyse de vos données. Comme d’habitude, les codes sources sont disponibles sur Github.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Bonjour, peut-on appliquer des méthodes de statistiques type MCMC et AIC/BIC pour une modélisation non linéaire univariable des données pour valider un modèle?