

L’objectif de cet article est de fournir un petit tuto rapide vous permettant d’accéder rapidement et facilement à votre cluster Hadoop via Hive et HDFS. Si vous faite un petit tour sur internet vous verrez qu’il y a pléthore de solutions et librairies pour cela. Il existe notamment une librairie Python qui s’appelle PyDev et qui est plutot efficace … si vous arrivez à l’installer correctement 😉
PySpark
Dans ce tuto, nous utiliserons PySpark qui comme son nom l’indique utilise le framework Spark. Rappelons juste ici que Spark n’est pas un langage de programmation mais un environnement ou un framework de calcul distribué. Par nature il est très donc utilisé avec Hadoop.
Nous allons lire et écrire des données dans hadoop. Il faut donc avoir en tête que Spark ne manipule pas de fichier mais des Resilient Distributed Dataset ou RDD.
Ces RDD ont pour caractéristiques :
- ils sont organisés en ligne : Attention car ces lignes ne peuvent pas excéder 2 Go. En pratique il est même conseillé de ne pas aller au-delà de quelques Mo.
- Il est quasi-impossible d’accéder à une partie du fichier précisément. Il faudra donc le parcourir en entier car bien sur les RDD n’ont pas d’index 🙁
- Ils fonctionnent comme des flux ou des curseurs (lecture ou écriture): on ne peut donc pas modifier un RDD !
- Ils sont distribués. L’ordre des lignes du dataset n’est pas connu à l’avance (Corollaire de cela, il ne stocke pas les noms des colonnes).
Voilà pour les gros inconvénients, mais grâce à la Librairie Pandas, nous verrons comment y palier facilement.
NB: installez PySpark via la commande $ pip install pyspark
Spark & Python
Disons le : Spark est implémenté en Java !
L’API PySpark est assez efficace mais ne sera jamais autant efficace et performante que l’API Java (ou scala). Néanmoins pour la plupars des projets de Machine Learning, PySpark fera parfaitement l’affaire. Et puis vous verrez elle est plutôt simple d’utilisation.
Cluster Hadoop
Coté Hadoop j’utiliserai pour ce tuto la distribution HortonWorks (HDP 2.6.4).
Vous pouvez télécharger la sandbox ici.
Une fois le cluster installé et configuré, vous pouvez accéder à la console d’administration AMBARI via l’URl : http://
Connectez-vous en tant qu’admin et vérifiez que les services HDFS et HIVE sont opérationnels :
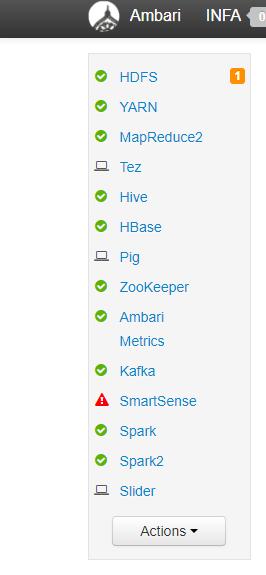
Récupérez ensuite le paramètre hive.
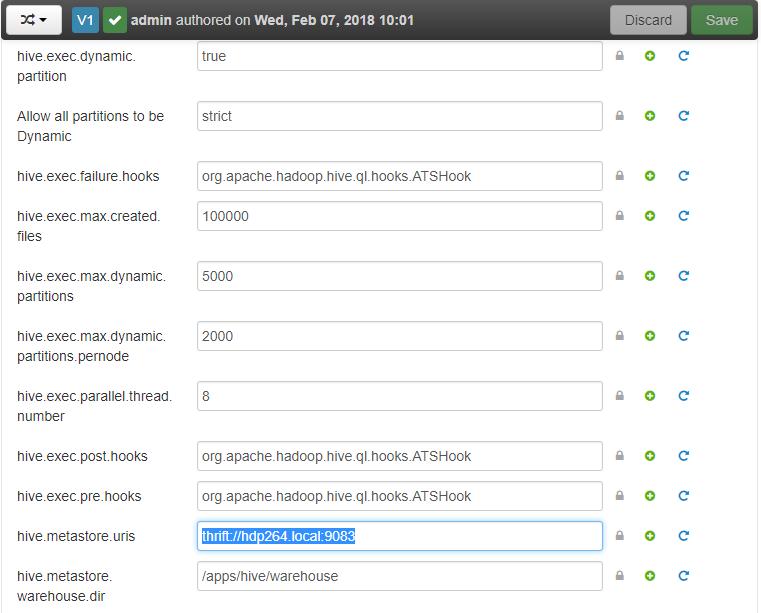
Dans mon cas je met de coté la valeur : thrift://hdp264.local:9083
Hadoop HDFS
Entrons dans le vif du sujet et voyons comment nous allons pouvoir écrire et lire un fichier dans un cluster Hadoop HDFS avec Python.
Quelques commandes utiles
Interagir avec HDFS est plutot simple en ligne de commande. Voici un petit memento :
Lister un répertoire :
$ hadoop fs -ls
Créer un répertoire :
$ hadoop fs -mkdir /user/input
Changer droits :
$ hadoop fs -chmod 777 /user
Envoyer fichiers :
$ hadoop fs -put /home/file.txt /user/input
Lire un fichier :
hadoop fs -cat /user/infa/Exp_Clients.csv
Récupérer fichier :
hadoop fs -get /user/output/ /home/hadoop_tp/
Ecriture d’un fichier dans HDFS avec PySpark
Vous savez ineragir avec HDFS en ligne de commande maintenant, voyons comment écrire un fichier avec Python (PySpark). Dans l’exemple ci-dessous nous allons créer un RDD avec 4 lignes et deux colonnes (data) puis l’écrire dans un fichier sous HDFS (URI : hdfs://hdp.local/user/hdfs/example.csv) :
import os
from pyspark.sql import SparkSession
import pandas as pd
os.environ["HADOOP_USER_NAME"] = "hdfs"
os.environ["PYTHON_VERSION"] = "3.5.6"
sparkSession = SparkSession.builder.appName("pyspark_test").getOrCreate()
data = [('data 1', 1), ('data 2', 2), ('data 3', 3), ('data 4', 4)]
df = sparkSession.createDataFrame(data)
df.write.csv("hdfs://hdp.local/user/hdfs/example.csv")
Vérifions que le fichier a bien été écrit. Pour cela dans la console Ambari, sélectionnez le « Files View » (icône matrice en haut à droite). Naviguez dans /user/hdfs comme ci-dessous :
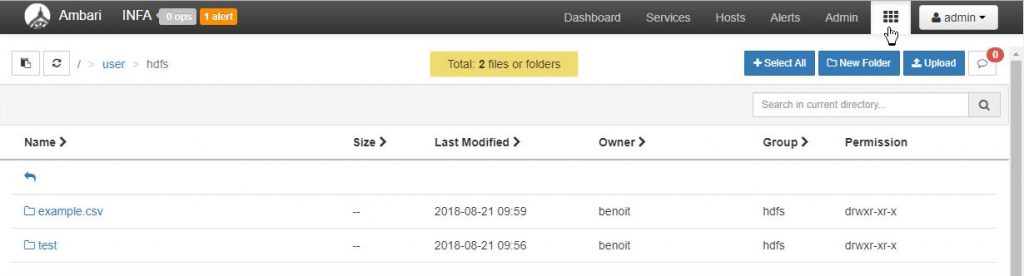
Bonne nouvelle le fichier example.csv est bien présent 🙂
Lecture d’un fichier dans HDFS avec PySpark
La lecture est tout aussi simple que l’écriture avec la commande sparkSession.read.csv :
import os
from pyspark.sql import SparkSession
import pandas as pd
os.environ["HADOOP_USER_NAME"] = "hdfs"
os.environ["PYTHON_VERSION"] = "3.5.6"
sparkSession = SparkSession.builder.appName("pyspark_test").getOrCreate()
df = sparkSession.read.csv('hdfs://hdp.local/user/hdfs/example.csv')
df.show()
La méthode show() affiche le contenu du fichier.
Hive
Nous venons de voir comment ecrire ou lire un fichier dans HDFS. Voyons maintenant comment nous pouvons interagir avec Hive avec PySpark.
Quelques commandes Hive utiles
On lance hive en ligne de commande simplement en tapant $ hive. Une fois le client hive opérationnel, il propose un prompt hive> avec lequel vous pouvez interagir :
Liste toutes les tables
hive> SHOW TABLES;
Liste toutes les tables finissant par e (Cf. expressions régulières):
hive> SHOW TABLES '.*e';
Description d’une table (colonnes):
hive> DESCRIBE INFA.EMPLOYEE;
Base de données :
hive> CREATE DATABASE [IF NOT EXISTS] userdb; hive>SHOW DATABASES; hive>DROP DATABASE IF EXISTS userdb;
Vous pouvez bien sur faire du HiveQL :
SELECT [ALL | DISTINCT] select_expr, select_expr, … FROM table_reference [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]] [LIMIT number]; hive> SELECT * FROM employee WHERE salary>30000;
« Requeter » Hive avec PySpark
Pour celà j’ai créé une table customers_prov dans Hive que nous allons requeter. Mais avant toute chose vous allez devoir préciser votre URI Hive (cad le parametre hive.
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession, HiveContext
import pandas as pd
SparkContext.setSystemProperty("hive.metastore.uris", "thrift://hdp.local:9083")
sparkSession = (SparkSession
.builder
.appName('pyspark_test')
.enableHiveSupport()
.getOrCreate())
df_spark = sparkSession.sql('select * from customers_prov')
df_spark.show()
Malheureusement les RDD sont peu exploitables à mon gout. Bien sur on aura quelques méthodes utiles:
- df_spark.schema() qui affiche le schéma
- df_spark.printSchema() : qui affiche le même schéma mais sous forme d’arbre
- etc.
Mais personnellement j’adore la commande magique qui transforme ces RDD en DataFrame Pandas : toPandas()
s = df_spark.toPandas()
Et voilà maintenant vous pouvez concevoir et travailler sur votre Modèle de Machine Learning 🙂
Retrouvez les sources de ce tuto dans des notebooks Jupyter sur Github
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.