

Qu’est-ce que le Web Scraping ?
Si l’on s’en réfère à Wikipédia le Web Scrapping « permet de récupérer le contenu d’une page web en vue d’en réutiliser le contenu ». Dit autrement le Web Scrapping consiste à récupérer des données du web via le contenu des pages html. C’est particulièrement utile quand vous avez surfé sur internet et trouvé les informations que vous cherchiez. Mais Aîe ! comment récupérer ces informations si le site ne les publie pas (sous forme d’API ou d’export CSV).
Tout le monde n’est pas ou n’a pas la vocation à être « Open Data » !

Le besoin est donc simple : dès lors que vous pouvez consulter des informations sur une page web de votre navigateur vous devriez pouvoir le récupérer grâce au Web Scrapping. Simple ? pas tant que cela malheureusement car si les données sont visualisable, certains site sont très malins et vont compliquer la vie de celui qui tente d’aspirer ses données. C’est de bonne guerre finalement 🙂
Pour les aspects littérature sachez juste que l’on parle de Web Scrapping mais aussi – et c’est la même chose – de data harvesting.
Si vous faite un peu le tour du web vous trouverez plusieurs outils (gratuits ou pas, Open Source ou pas) qui peuvent aussi vous aider rapidement. Je citerai par exemple :
- OctoParse : https://www.octoparse.com/
- ParseHub : https://www.parsehub.com/
- Contentgrabber : https://contentgrabber.com/
- Mozenda : https://www.mozenda.com/
- etc.
Dans cet article nous allons voir comment récupérer des données publiées sur une site Web et puis nous les écrirons de manière exploitable – c’est à dire sous forme tabulaire – dans un fichier csv. Evidemment on n’utilisera pas d’outil … ça serait bien trop simple 😉
Votre mission si vous l’acceptez
Votre cible sera le site jeuvideo.com. Et plus particulièrement la liste des meilleurs jeux vidéos : http://www.jeuxvideo.com/meilleurs/

L’idée est donc tout aussi simple, récupérer la liste des meilleurs jeux vidéos (les 200 meilleurs par exemple) et d’écrire cette liste dans un fichier CSV.
On récupérera bien sur à minima:
- le nom du jeu vidéo
- sa description
- sa date de sortie
- sa note de test
- sa note des joueurs
Mise en œuvre simplement avec Python
Comme je le disais plus haut, il existe plusieurs outils qui pourraient le faire automatiquement pour vous mais j’ai choisi de vous montrer comment le faire avec Python. Vous verrez que c’est vraiment très simple et totalement accessible.

Pour commencer, bien sur il faut aller sur la page que vous voulez scraper et regarder si vous trouvez une structure en matière de styles CSS. Évidemment si vous ne connaissez pas les feuilles de style cette étape sera quelque hardue … mais pas impossible car avec les browsers modernes vous aurez de l’aide 🙂
Récupération de la structure de style CSS
Dans mon exemple j’utilise Firefox. Alors sélectionnez juste la partie que vous souhaitez récupérer et faite un clic droit dessus. Choississez enfin « Examiner l’élément » pour faire apparaître le contenu de la page HTML. Un nouveau panneau doit apparaître en dessous avec ce fameux contenu HTML (Cf. image ci dessous). Vous verrez dans ce panneau une ligne en surbrillance indiquant le code HTML correspondant à la zone que vous aviez sélectionné:
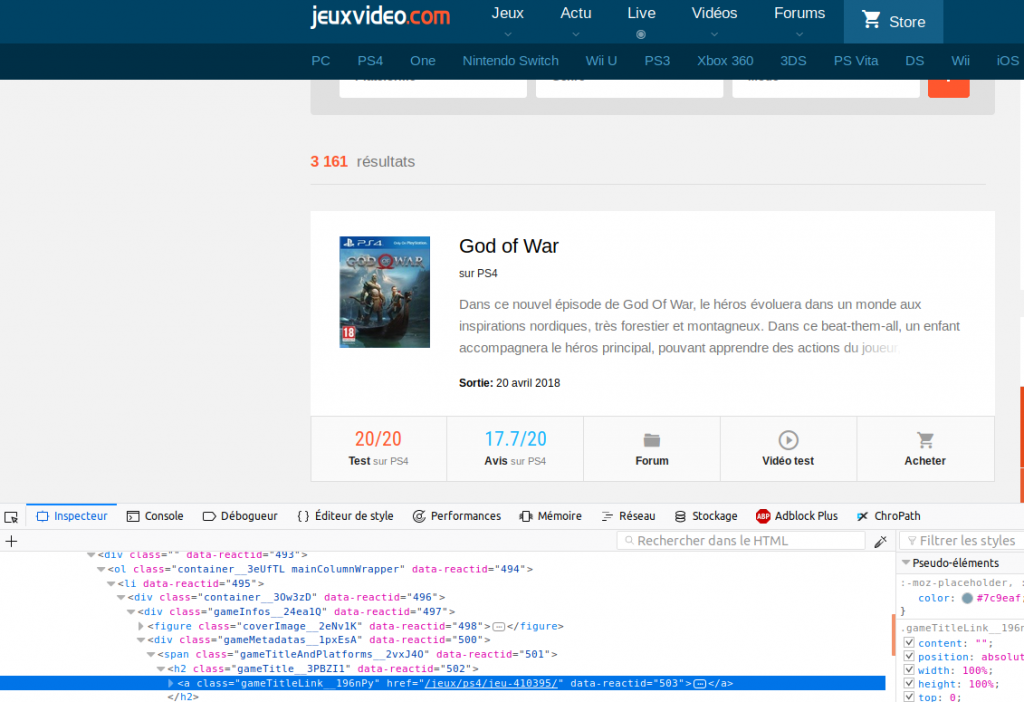
Dans notre exemple nous avons sélectionné le titre du jeu (God Of War). Et on constate que c’est un hyperlien (tag A) qui a pour classe CSS gameTitleLink__196nPy. Très bien on garde ça sous le coude pour plus tard, et on va récupérer par là même les autres informations voulues (description, notes, sortie).
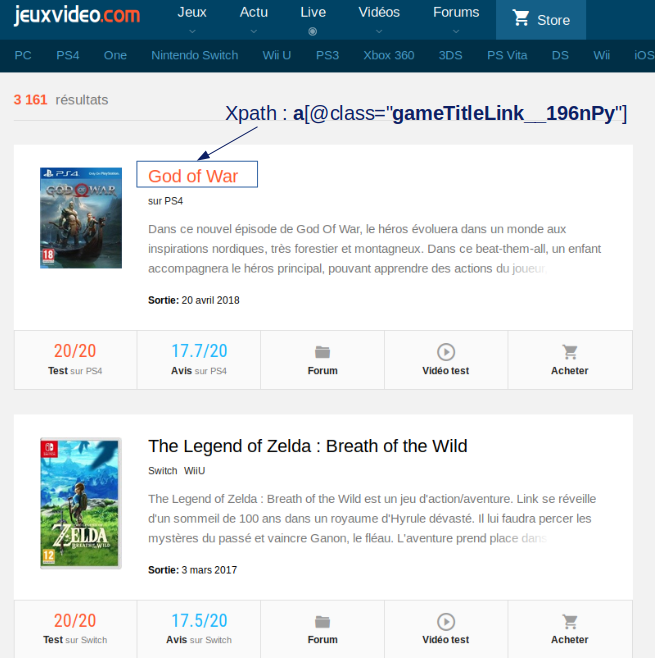
Pourquoi nous récupérons les classes CSS ? et bien tout simplement parcequ’elle vont nous permettre de pointer via le code Python directement sur les éléments voulus grâce au langage de requête XPATH. Dans notre exemple ci-dessus par exemple le titre (enfin tous les titres) se retrouve via le chemin XPATH: //a[@class= »gameTitleLink__196nPy »]
Scrapons !
Nous avons maintenant les informations nécessaire pour récupérer la liste des meilleurs jeux vidéos selon le site jeuvideo.com. Commençons par ouvrir un notebook Jupyter pour codez le scraping en Python.
import requests
import lxml.html as lh
page = requests.get('http://www.jeuxvideo.com/meilleurs/')
doc = lh.fromstring(page.content)
Le code ci-dessus récupère le contenu de la page http://www.jeuxvideo.com/meilleurs/
nomJeux = doc.xpath('//a[@class="gameTitleLink__196nPy"]')
desc = doc.xpath('//p[@class="description__1-Pqha"]')
sortie = doc.xpath('//span[@class="releaseDate__1RvUmc"]')
test = doc.xpath('//span[@class="editorialRating__1tYu_r"]')
avis = doc.xpath('//span[@class="userRating__1y96su"]')
for i in range(len(nomJeux)):
print(nomJeux[i].text_content().strip() + "\n" + \
desc[i].text_content().strip() + "\n" + \
sortie[i].text_content().strip()+ "\n" + \
test[i].text_content().strip() + "\n" + \
avis[i].text_content().strip() + "\n")
Ensuite nous allons récupérer les zones pointées par les références XPATH et les afficher. Et voilà c’est magique non ?
Magique mais pas tellement exploitable en fait, je vous propose donc de mettre ces données dans un DataFrame Pandas. Pour cela on va créer une fonction qui va récupérer les données (via XPATH) et va créer un DataFrame qui prend une donnée pointée par colonne et on aura par là même un jeu par ligne avec toutes ces informations :
def getPage(url):
page = requests.get(url)
doc = lh.fromstring(page.content)
# Get the Web data via XPath
content = []
for i in range(len(tags)):
content.append(doc.xpath(tags[i]))
# Gather the data into a Pandas DataFrame array
df_liste = []
for j in range(len(tags)):
tmp = pd.DataFrame([content[j][i].text_content().strip() for i in range(len(content[i]))], columns=[cols[j]])
tmp['key'] = tmp.index
df_liste.append(tmp)
# Build the unique Dataframe with one tag (xpath) content per column
liste = df_liste[0]
for j in range(len(tags)-1):
liste = liste.join(df_liste[j+1], on='key', how='left', lsuffix='_l', rsuffix='_r')
liste['key'] = liste.index
del liste['key_l']
del liste['key_r']
return liste
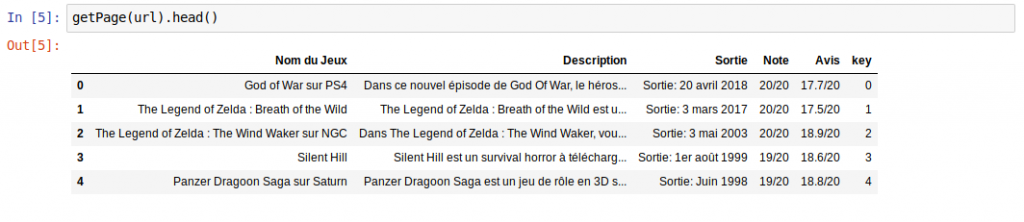
Voilà le résultat :
Quid de la pagination ?
Vous aurez remarqué que nous n’avons récupéré que les 20 meilleurs jeux vidéos. C’est plutôt logique vu que le site jeuvideo.com affiche les données par page de 20 ! Si on veut récupérer plus d’informations nous allons devoir gérer la pagination automatique de ce site. Pour faire simple nous allons devoir boucler sur le critère HTTP qui permet de gérer cette pagination à savoir http://www.jeuxvideo.com/meilleurs/?p=X pour avoir la page X.
Voici donc la fonction qui va permettre de boulcler pour récupérer les _nbPages x 20 meilleurs jeux vidéos :
def getPages(_nbPages, _url):
liste_finale = pd.DataFrame()
for i in range (_nbPages):
liste = getPage(_url + uri_pages + str(i+1))
liste_finale = pd.concat([liste_finale, liste], ignore_index=True)
return liste_finale
liste_totale = getPages(nbPages, url)
Pour terminer vous n’avez plus qu’à sauvegarder par exemple vos données dans un fichier csv :
liste_totale.to_csv('meilleursjeuvideo.csv', index=False)
L’idée de cet article était de vous montrer que le scraping peut être une tâche très simple (comme très complexe en fait) et que surtout cette technique pouvait être très utile pour récupérer des données par forcément mises à disposition.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Hello.
Pb ligne 4 de getPages(_nbPages, _url).
Pourrait-on avoir une version qui fonctionne de bout en bout ?
Merci !!
Bonjour Mr T 🙂
Pas de soucis, en fait tous les sources de mes posts sont dans Github.
Celui ci est disponible ici dans un notebook Jupyter : https://github.com/datacorner/les-tutos-datacorner.fr/blob/master/data-access/webscraping/wscrap_1.ipynb
A bientôt.
Benoit
bonjour monsieur
s’il vous plait comment peut on recuperer une grande quantite de données texte de plusieurs sites( affin de faire entrainer un gpt2 sur ces données) en utilisant la methode web scrapping?