
Vélib Metropole
Le service Vélib Metropole permet la location à la demande de vélos dans Paris et sa petite couronne. Bonne nouvelle, Paris et son Open Data fournit un service (API) d’accès aux disponibilités des vélos dans les stations. Qu’à cela ne tienne, et si on analysait de plus près ces données ?

Les données de l’API
Les données sont en accès via la licence Open Database License (ODbL). En accédant sur le site de l’API on va pouvoir récupérer facilement plusieurs informations :
- Nombre de bornes disponibles
- Nombre vélo en PARK+
- Nombres de bornes en station
- Nombre de vélo mécanique
- Nombre vélo électrique
- Nom de la station
- Etat des stations
- etc.
Chose importante: l’API est accessible via REST/GET et renvoie des données au format JSON.
Afin de tester l’API je vous suggère d’utiliser le portail OpendataSoft qui permet d’interagir avec cette dernière plus facilement. Sinon vous pouvez taper directement cette URL dans votre navigateur et voir le résultat :
https://data.opendatasoft.com/api/records/1.0/search/?dataset=velib-disponibilite-en-temps-reel%40parisdata&facet=overflowactivation&facet=creditcard&facet=kioskstate&facet=station_state
Par contre nous avons un soucis … aucun horodatage n’est prévu ! il s’agit d’une interrogation temps réel des stations !
Interroger l’API toutes les heures
Nous n’avons pas d’horodatage ! qu’à celà ne tienne, nous allons le créer. Pour celà nous allons créer un programme (ici en Python) qui va interroger cette API toutes les heures. Nous collecterons ainsi les données à intervalle régulier et nous stockerons les résultats dans un fichiers plat pour l’analyser ensuite.
Pour appeler de manière régulière une fonction Python nous ne ferons pas de « wait » mais nous utiliserons ses possibilités multi-threading via le module threading et sa fonction Timer. Voici le principe d’utilisation :
from threading import Timer
def update():
getData()
set_timer()
def set_timer():
Timer(durationinsec, update).start()
def main():
update()
main()
L’appel d’API REST est tout aussi simple et pour celà nous utiliserons le module request. L’appel s’effectue via 2 lignes de codes, et ensuite nous n’aurons qu’à vérifier le code de retour (200) pour savoir si l’appel s’est bien effectué.
Les données sont récupérées au format JSON, mais bonne nouvelle l’arbre constitué est très simple et il nous suffira de balayer les noeuds « records » pour récupérer les stations une par une.
Voici le code Python complet (accessible aussi via Github) :
from threading import Timer
import requests
import pandas as pd
from time import localtime, strftime
def update():
getData()
set_timer()
def set_timer():
Timer(durationinsec, update).start()
def main():
update()
def getData():
global iteration
nbrows = 1500
url = "https://opendata.paris.fr/api/records/1.0/search/?dataset=velib-disponibilite-en-temps-reel%40parisdata&rows=" + str(nbrows) + "&facet=overflowactivation&facet=creditcard&facet=kioskstate&facet=station_state"
mytime = strftime("%Y-%m-%d %H:%M:%S", localtime())
resp = requests.get(url)
if resp.status_code != 200:
print(mytime, " - ", iteration, " - Erreur dans la récupération des données")
else:
data = resp.json()
dff = pd.DataFrame(columns =['Timer', 'ID', 'Station', 'Code Station', 'Type de stations', 'Etat de la station',
'Nb bornes disponibles', 'Nombres de bornes en station', 'Nombre vélo en PARK+',
'Nb vélo mécanique', 'Nb vélo électrique',
'geo'])
for rec in data['records']:
dff.loc[len(dff)] = [mytime,
rec['recordid'],
rec['fields']['station_name'],
rec['fields']['station_code'],
rec['fields']['station_type'],
rec['fields']['station_state'],
rec['fields']['nbfreeedock'],
rec['fields']['nbedock'],
rec['fields']['nbbikeoverflow'],
rec['fields']['nbbike'],
rec['fields']['nbebike'],
rec['fields']['geo']]
if int(data['nhits']) > 0:
with open("vélib_batch_parheure.csv", 'a') as f:
dff.to_csv(f, header=True, index=False)
print(mytime, " - ", iteration, " - Fin de la récupération, Nb de lignes récupérées: ", data['nhits'])
else:
print(mytime, " - ", iteration, " - Pas de données à récupérer.")
iteration = iteration + 1
durationinsec = 1*60*60
iteration = 1
main()
Il ne reste qu’à lancer le script ci-dessus pendant plusieurs jours et de récupérer ensuite le fichier vélib_batch_parheure.csv pour analyser son contenu.
Analysons le résultat
Nous allons utiliser Tableau sur le fichier CSV qui vient d’être généré. un certain nombre de préparation des données seront quand même nécessaire :
- La récupération de la latitude et longitude à partir des données au format [X, Y]. Pour celà on utilisera l’assistant graphique (onglet data) pour récupérer les coordonnées.
- On rajoutera des KPIs comme le ratio de disponibilité ([Nb bornes disponibles] / [Nombres de bornes en station])
Ensuite un dashboard pourra par exemple présenter les problèmes de disponibilité des vélos par station et ce par heure comme ci-dessous :
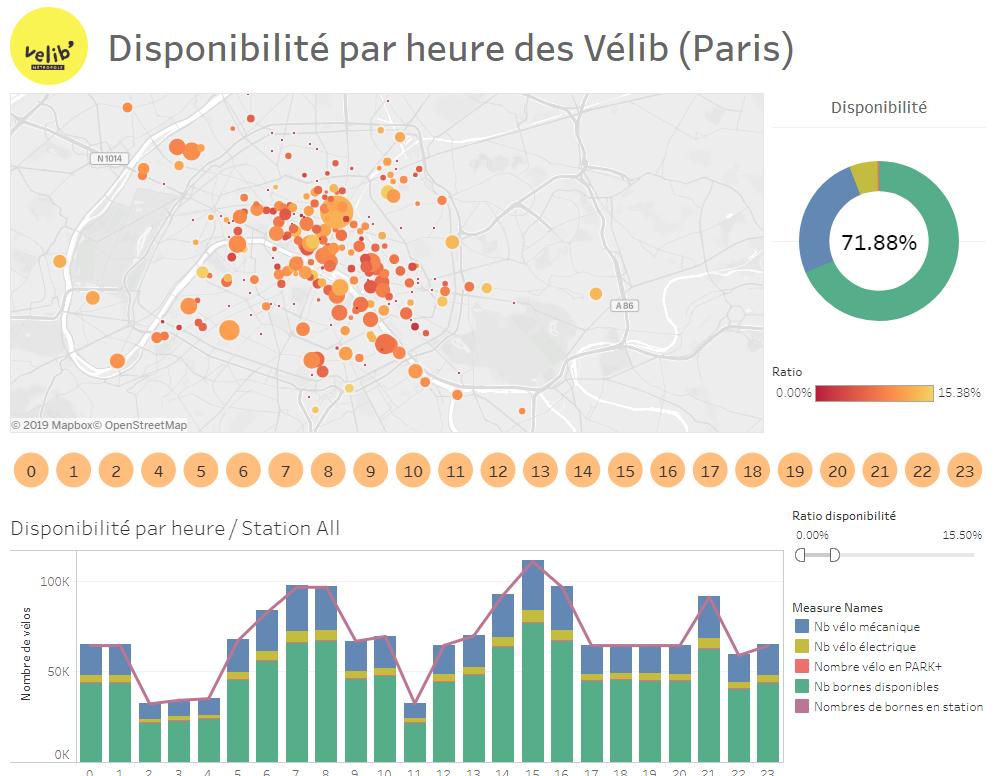
Ce dashboard est disponible et téléchargeable dans Tableau Public ici.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.