
Plotly est une société mais surtout une librairie très utilisée dans le monde Python. Pourquoi ? et bien parce que cette librairie est assez évoluée et qu’elle permet de faire des graphes de manière simple et efficace. Vous voulez découvrir comment elle fonctionne, suivez le guide, dans cet article nous allons voir comment installer et utiliser via divers visualisation cette librairie. Un seul prérequis: connaître un tout petit peu Python. Coté environnement j’utilisera Google Colab.
Installation
C’est vraiment l’un des aspects que je préfère avec Python … l’installation d’une nouvelle librairie se fait avec une facilité déconcertante avec pip:
pip install plotlySi vous utilisez colab comme moi vous devriez avoir pour réponse :
Requirement already satisfied: plotly in /usr/local/lib/python3.7/dist-packages (4.4.1)
Requirement already satisfied: retrying>=1.3.3 in /usr/local/lib/python3.7/dist-packages (from plotly) (1.3.3)
Requirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from plotly) (1.15.0)Voilà la librairie est prête à l’emploi, il ne reste plus qu’a la référencer via quelques imports Python:
import numpy as np
import pandas as pd
import plotly.graph_objects as go
import plotly.express as px
from plotly.subplots import make_subplotsPréparation du dataset
Afin de visualiser les différents graphes nous allons rapidement préparer un dataset à partir de celui qui est fournit par défaut avec Google Colab: /content/sample_data/california_housing_train.csv
Ce jeu de données (utilisé dans le deuxième chapitre du récent livre d’Aurélien Géron « Hands-On Machine learning with Scikit-Learn and TensorFlow »). Les données référencent les maisons trouvées dans un district de Californie et propose certaines statistiques basées sur les données du recensement de 1990 aux US.
Les colonnes sont les suivantes, leurs noms sont assez explicites:
- longitude et latitude
- housingmedianage
- total_rooms
- total_bedrooms
- population
- households
- median_income
- medianhousevalue
Toutes ces données ne nous interressent pas vraiment, à partir de ce jeu de données nous allons créer deux nouveaux jeux de données:
- Un jeu de données aggrégé par age médian
- Un jeu de données (encore plus aggrégé) par catégorie d’age médian (pour celà nous allons créer une nouvelle donnée catégorielle permettant de regrouper les ages médian)
Récupérons tout d’abord ce jeu de données. Comme je vous l’ai dit, ce jeu est proposé par défaut dans colab:
dataset = pd.read_csv("/content/sample_data/california_housing_train.csv")
dataset.head() longitude latitude housing_median_age total_rooms total_bedrooms population households median_income median_house_value
0 -114.31 34.19 15.0 5612.0 1283.0 1015.0 472.0 1.4936 66900.0
1 -114.47 34.40 19.0 7650.0 1901.0 1129.0 463.0 1.8200 80100.0
2 -114.56 33.69 17.0 720.0 174.0 333.0 117.0 1.6509 85700.0
3 -114.57 33.64 14.0 1501.0 337.0 515.0 226.0 3.1917 73400.0
4 -114.57 33.57 20.0 1454.0 326.0 624.0 262.0 1.9250 65500.0Créons maintenant nos deux jeux de données agrégés :
def group(age):
if (age < 10):
return "0-10"
elif (age < 20):
return "10-20"
elif (age < 30):
return "20-30"
elif (age < 40):
return "30-40"
else:
return "40+"
# Create an aggregat by age group
ds_grp_age = dataset
ds_grp_age["agegroup"] = [group(x) for x in ds_grp_age["housing_median_age"] ]
ds_grp_age = ds_grp_age[['agegroup', 'median_house_value', 'median_income', 'total_rooms', 'population']]
gpr_age = pd.DataFrame()
gpr_age["value"] = ds_grp_age.groupby(by=['agegroup']).median_house_value.mean()
gpr_age["age"] = ds_grp_age.groupby(by=['agegroup']).agegroup.max()
gpr_age["income"] = ds_grp_age.groupby(by=['agegroup']).median_income.mean()
gpr_age["rooms"] = ds_grp_age.groupby(by=['agegroup']).total_rooms.mean()
gpr_age["population"] = ds_grp_age.groupby(by=['agegroup']).population.mean()
# Create an aggregat by age
ds_age = dataset
ds_age = ds_age[['median_house_value', 'median_income', 'total_rooms', 'population', 'housing_median_age']]
agg_age = pd.DataFrame()
agg_age["value"] = ds_age.groupby(by=['housing_median_age']).median_house_value.mean()
agg_age["age"] = ds_age.groupby(by=['housing_median_age']).housing_median_age.max()
agg_age["income"] = ds_age.groupby(by=['housing_median_age']).median_income.mean()
agg_age["rooms"] = ds_age.groupby(by=['housing_median_age']).total_rooms.mean()
agg_age["population"] = ds_age.groupby(by=['housing_median_age']).population.mean()
agg_age["agegroup"] = agg_age["age"].apply(group)Visualisation de base
Graphe à points
Le premier graphe auquel on pense quand on a deux données de type continues est bien sur un graphe à point (scatter plot). Avec plotly rien de plus simple :
fig = go.Figure(data=go.Scatter(
x=agg_age["age"],
y=agg_age["value"],
mode='markers'))
fig.show()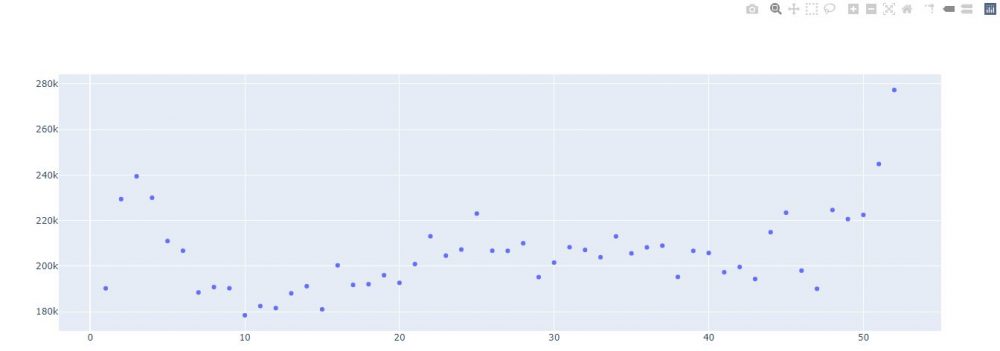
L’interet de Plotly ne s’arrête pas ici. Premièrement le graphique est interactif: si vous passez la souris sur les points vous verrez des informations (les coordonnées) s’afficher dans une info bulle:
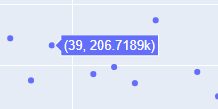
Deuxièmement, vous aurez sans doute remarqué qu’en haut à droite on trouve plusieurs boutons :

Ces boutons permettent de donner plus de possibilités d’interaction avec l’utilisateur :
- Télécharger le graphe en png
- Zoomer
- Déplacer le graphe par rapport à ses axes par défaut
- Sélectionner des éléments
- Réinitialiser les axes
- etc.
Graphe avec des lignes
Bien sur Plotly propose des fonctions avancées pour créer des graphes et en combiner plusieurs. Pour combiner plusieurs graphes ensemble il suffit d’empiler des appels à la fonction add_trace(). Voyons comment simplement créer 2 graphe en lignes ensemble.
fig = go.Figure(data=go.Scatter(x=agg_age["age"], y=agg_age["population"], mode='lines+markers', name='population'))
fig.add_trace(go.Scatter(x=agg_age["age"], y=agg_age["rooms"], mode='lines+markers', name='rooms'))
fig.show()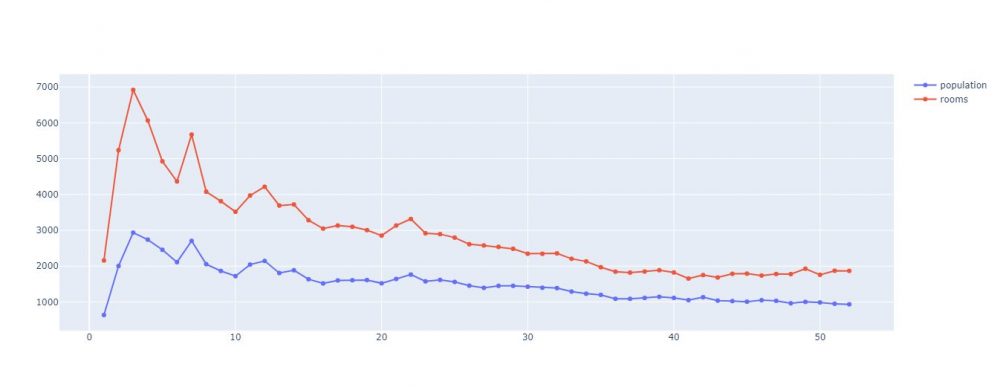
Vous remarquerez aussi que Plotly change automatiquement la couleur.
Diagramme en barre
Dés lors que l’on a des données catégorielles avec des données continues, bien souvent on utilise des graphe en barre (bar chart):
fig = go.Figure(data=go.Bar(x=gpr_age["age"], y=gpr_age["rooms"]))
fig.show()
Camembert
Les diagramme cammembert ne sont guère plus complexes:
fig = px.pie(gpr_age, values='rooms', names='age', title='Rooms / Age')
fig.show()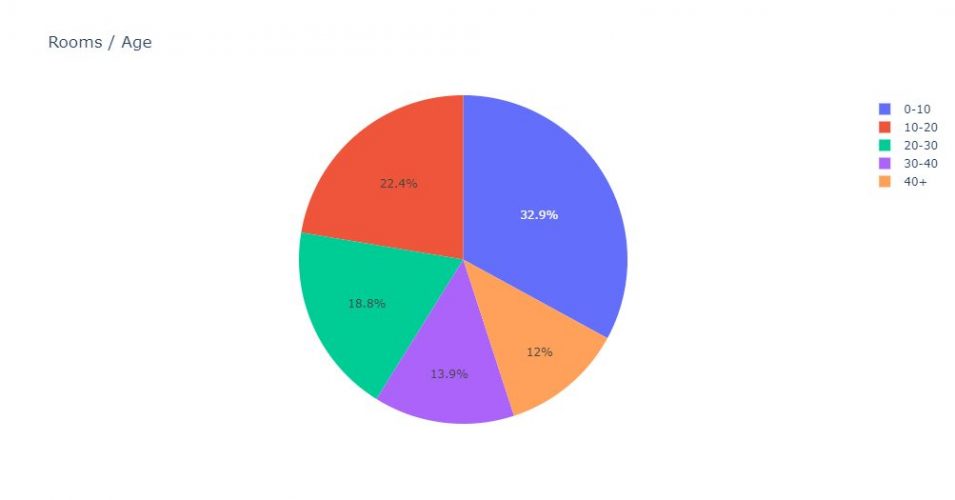
Viz plus complexes
Quand on fait de la visualisation de données sur un jeu de données un peu plus complexe on peut jouer sur 3 (voire 4) éléments:
- Les coordonnées du point (ce que nous avons fait plus haut)
- Son épaisseur
- Sa couleur
- et parfois même la forme du point
Voyons comment élaborer une visualisation plus étoffée avec Plotly. pour celà il nous suffit de rajouter les attributs color et size avec les colonnes à visualiser dans le graphique. On va même rajouter quelques informations supplémentaires dans l’info bulle (population):
fig = px.scatter(agg_age,
x="age",
y="income",
color="value",
size='rooms',
hover_data=['population'])
fig.show()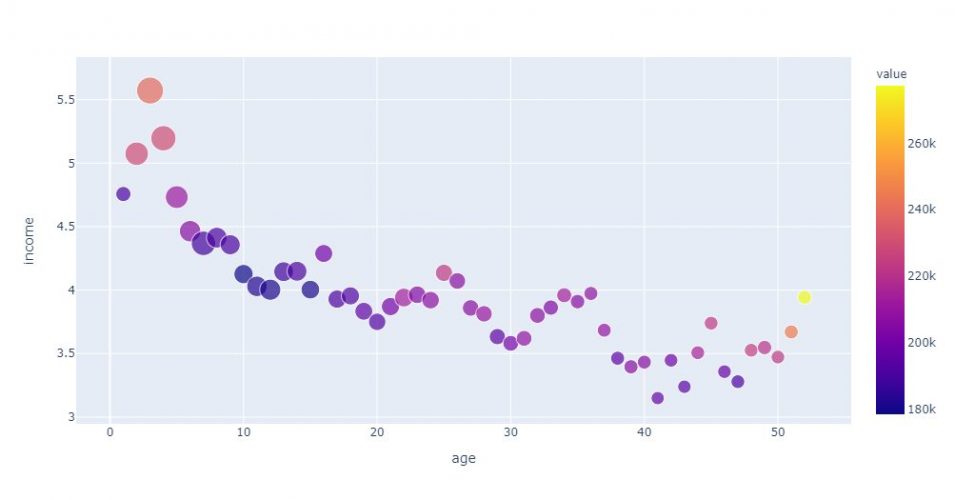
Avec Plotly on peut aussi empiler plusieurs graphes qui vont se décliner automatiquement via une donnée catégorielle par exemple. Dans l’exemple ci-dessous Plotly va créer autant de graphes séparés qu’il y a de croupe d’age:
fig = px.bar(
agg_age,
x="population",
y="income",
color="rooms",
facet_col="agegroup",
title="title"
)
fig.show()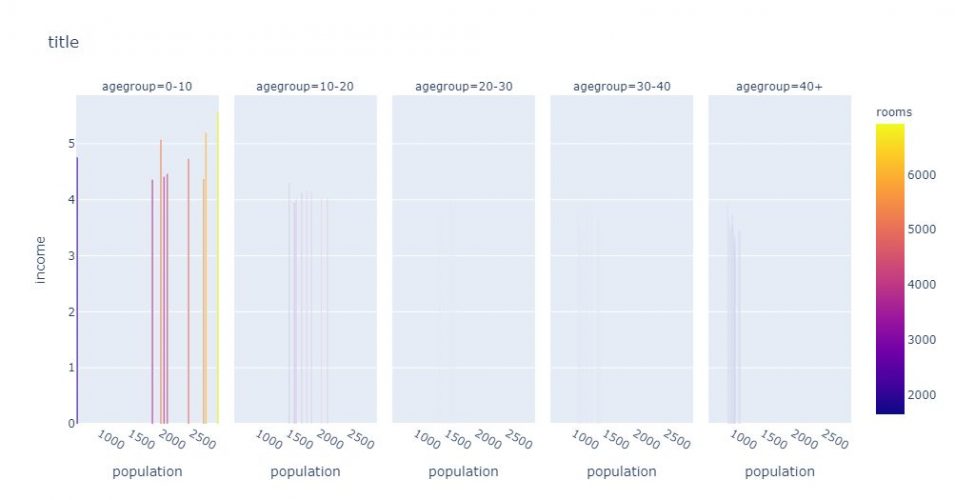
L’empilement peut aussi être vertical, on utilise alors l’attribut facet_row à la place de facte_col:
fig = px.scatter(
agg_age,
x="population",
y="income",
color="rooms",
facet_row="agegroup",
title="title"
)
fig.show()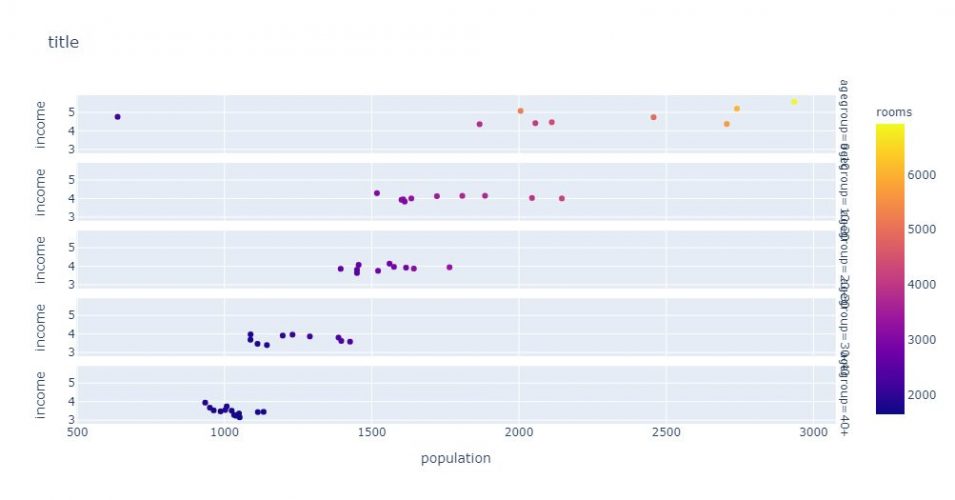
Pour terminer il peut être vraiment très utile dés lors que les echelles sont trop différentes par exemple d’afficher des graphes différents sous forme de grilles. Une fois de plus Plotly s’avère très efficace dans cet exercice. Il suffit de créer un objet subplot via make_suplot, delui définir les dimensions de la grille, puis d’y affecter des visualisations:
fig = make_subplots(rows=1, cols=2)
fig.add_bar(x=gpr_age["age"],
y=gpr_age["rooms"],
marker=dict(color="LightBlue"),
name="A",
row=1,
col=1)
fig.add_scatter(x=agg_age["age"],
y=agg_age["population"],
marker=dict(size=15, color="Blue"),
mode="markers",
name="B",
row=1,
col=2)
fig.show()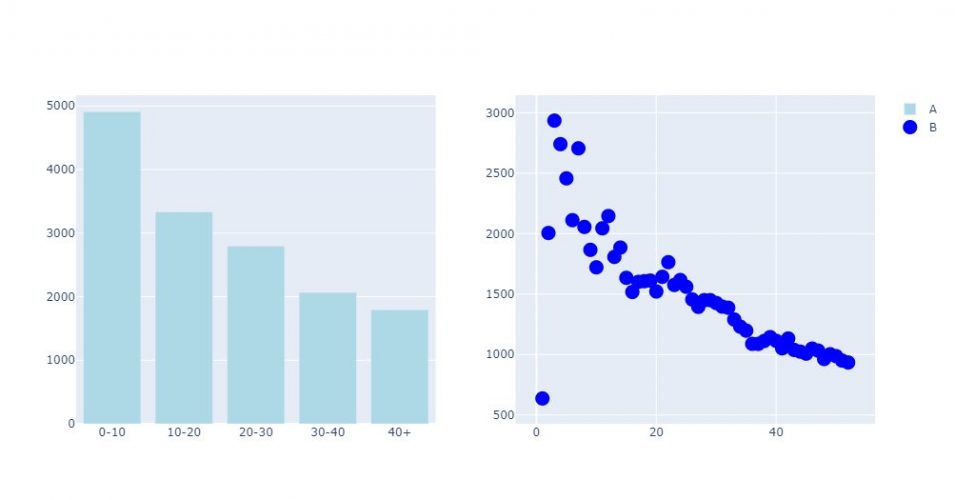
Conclusion
Plotly est décidément une librairie riche et simple d’utilisation. Evidemment impossible de ne pas se poser la question Plotly ou Matplotlib ? Coté rendu, capacité et complexité je dirais qu’il n’y a pas photo tant plotly permet de créer des visualisation plus évoluées. Coté simplicité ? peut être un léger avantage avec Matplotlib, et encore ! coté intégration, popularité et « standard » on retrouve un peut partout (raison historique) Matplotlib.
Retrouvez le notebook de ce tuto ici
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.