by
by Index
Hyper-parameters!
Your machine learning model is ready. You have adjusted the characteristics well to match the business needs and above all you have refined them so that they are better taken into account by the algorithm of your choice. Unfortunately, your work as a DataScientist is not finished and after the job cap you will have to put on that of the statistician. It is indeed in this phase of optimization that you will have to adjust the execution of the algorithm of your choice. In short, you will have to choose the hyper-parameters that will give you the best result.
Make no mistake, this choice is far from trivial and will have major consequences on future predictions.
But what are hyper-parameters?
Hyper-parameters are in fact the adjustment parameters of the various Machine Learning algorithms (SVC, Random Forest, Regression, KMeans, etc.). They are obviously different depending on the algorithm you use.
For example if you use the Gradient Boosting classification algorithm of Scikit-Learn you will have a certain number of hyper-parameters to define. Of course a certain number are defined with default values but it will be essential to “challenge” these values
class sklearn.ensemble.GradientBoostingClassifier(
loss=’deviance’,
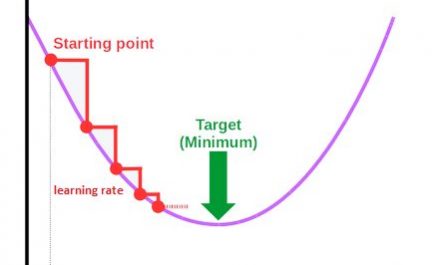
learning_rate=0.1,
n_estimators=100,
subsample=1.0,
criterion=’friedman_mse’,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_depth=3,
min_impurity_decrease=0.0,
min_impurity_split=None,
init=None,
random_state=None,
max_features=None,
verbose=0,
max_leaf_nodes=None,
warm_start=False,
presort=’auto’)
Obviously, nothing beats the official documentation to know the usefulness of a given hyper-parameter (learning_rate, n_estimators, etc.). But from there to finding the perfect fit that will give you the best score… that’s another matter.
Tuning hyper-parameters
A first approach consists in using the search by grid (Grid Search). The idea is actually quite simple: you position a list of possibilities for each of the hyper-parameters and for each of the combinations you will train your model and then calculate its score. In the end, of course, you will only keep the best settings.
It is an interesting and powerful technique but which has a very big drawback. You will have to be patient because your model will have to be trained on all the combinations, which can constitute a large number of trials. On the other hand, you will only have to do this once!
To do these tests you can simply code yourself, or use the scikit-learn library which provides the GridSearchCV function. Now let’s take an example with the RandomForest and look for the 3 best hyper-parameters: n_estimators, max_features and random_state.
To do this “grid-search” with Scikit-Learn, all you have to do is create a Python dictionary (here param_grid_rf) with the hyper-parameters to set and especially the values you want to test. Then you just have to train the GridSearchCV class like any other algorithm (with the fit method).
param_grid_rf = { 'n_estimators' : [800, 1000],
'max_features' : [1, 0.5, 0.2],
'random_state' : [3, 4, 5]}
grid_search_rf = GridSearchCV(RandomForestClassifier(), param_grid_rf, cv=5)
grid_search_rf.fit(Xtrain, y)
The grid_search_rf object will keep the correct settings and can directly call the predict () function for example. You can also see which setting was elected via the best_params_ and best_estimator_ properties. Of course the score method gives you the best score obtained with the best combination.
print ("Score final : ", round(grid_search_rf.score(Xtrain, y) *100,4), " %")
print ("Meilleurs parametres: ", grid_search_rf.best_params_)
print ("Meilleure config: ", grid_search_rf.best_estimator_)
NB: Another alternative (but which is better suited to Deep Learning) is to use a random grid via the RandomizedSearchCV class.
Procedure
So, of course, this tool, as practical as it is, is not magic and cannot replace know-how and experience. For one obvious reason: you can’t pass all the possible parameters to it! Now if the latter does not allow you to find the right parameters straight away (because too many combinations as mentioned above) I recommend a stepwise approach:
- First take the important parameters (starting of course with the mandatory parameters), then adjust the optional parameters.
- Take a dichotomy approach: take spaced values first, then close the gap.
But above all … give way to your intuition and your experience