by
by In a previous article we saw how the SpaCy library could help us analyze and especially exploit textual data. We will see in this article how to use the other (somewhat competitive, but not that much) NLTK library of Python.
Index
Installation of NLTK
To start we need to install the library. For that you must of course already have Python on your machine and then use PIP (package installer for Python) to install the nltk library:
pip install nltk
It’s not really finished, because once the library is installed, you must now download the entire NLTK corpus in order to be able to use its functionalities correctly.
A corpus is a set of documents, artistic or not (texts, images, videos, etc.), grouped together for a specific purpose.
Wikipedia
In our case, we understand by corpus only the textual elements.
To install these famous NLTK corpuses, and if like me you are using Jupyter simply type:
import nltk
nltk.download()
Wait a few seconds and a window should open:
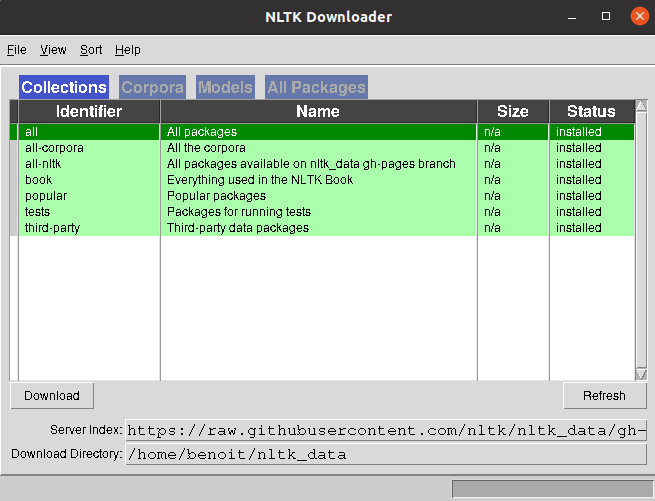
We are not going to be selective and take everything for this tutorial. Select ” All ” and click the Download button in the lower left corner of the window. Then wait until everything is downloaded to your destination folder …
Let’s start!
Now that our NLTK environment is ready, we will see together the basic functions of this library. For that we will use this text:
Wikipedia is an online, universal, multilingual, wiki-based collective encyclopedia wiki project. Do you like wikipedia encyclopedia?
Then import the libraries that will be necessary:
from nltk.corpus import stopwords
from nltk import word_tokenize
from nltk.tokenize import sent_tokenize
import re
data = u"""Wikipédia est un projet wiki d’encyclopédie collective en ligne, universelle, multilingue et fonctionnant sur le principe du wiki. Aimez-vous l'encyclopédie wikipedia ?"""
Les “stops words”
The “stop words”
First of all, it will be necessary to remove all the words that do not really add value to the overall analysis of the text. These words are called “stop words” and of course this list is specific to each language. Good news, NLTK offers a list of stop words in French (not all languages are available):
french_stopwords = set(stopwords.words('french'))
filtre_stopfr = lambda text: [token for token in text if token.lower() not in french_stopwords]
Thanks to Python’s lambda function, we created a small function that will allow us in a single line to filter a text from the list of French stop words.
french_stopwords = set (stopwords.words (‘french’)) filtr_stopfr = lambda text: [token for token in text if token.lower () not in french_stopwords]
Thanks to Python’s lambda function, we created a small function that will allow us in a single line to filter a text from the list of French stop words.
filtre_stopfr( word_tokenize(data, language="french") )
['Wikipédia',
'projet',
'wiki',
'’',
'encyclopédie',
'collective',
'ligne',
',',
'universelle',
',',
'multilingue',
'fonctionnant',
'principe',
'wiki',
'.',
'Aimez-vous',
"l'encyclopédie",
'wikipedia',
'?']That’s all the words (like articles, etc.) have been removed from the global wordlist. This function is really useful, compare for example with a filter which would only use RegEx:
sp_pattern = re.compile( """[\.\!\"\s\?\-\,\']+""", re.M).split
sp_pattern(data)
Tokenization
With NLTK you can split by word with the function word_tokenize (…) or by sentence sent_tokenize (…). Let’s start with a breakdown by sentence:
sent_tokenize(data, language="french")
['Wikipédia est un projet wiki d’encyclopédie collective en ligne, universelle, multilingue et fonctionnant sur le principe du wiki.',
"Aimez-vous l'encyclopédie wikipedia ?"]Interesting but the tokenization by word is even more of course:
word_tokenize(data, language="french")
['Wikipédia',
'est',
'un',
'projet',
'wiki',
'd',
...
'Aimez-vous',
"l'encyclopédie",
'wikipedia',
'?']And if we combine this function with the stop words filter seen previously, it’s even more interesting:
filtre_stopfr( word_tokenize(data, language="french") )
['Wikipédia',
'projet',
'wiki',
'’',
'encyclopédie',
'collective',
'ligne',
',',
'universelle',
',',
'multilingue',
'fonctionnant',
'principe',
'wiki',
'.',
'Aimez-vous',
"l'encyclopédie",
'wikipedia',
'?']Distribution frequency of values
It can be interesting to have the frequency of distribution of the values, for that there is of course a function FreqDist ():
fd = nltk.FreqDist(phfr)
print(fd.most_common())
[('wiki', 2), (',', 2), ('Wikipédia', 1), ('projet', 1), ('’', 1), ('encyclopédie', 1), ('collective', 1), ('ligne', 1), ('universelle', 1), ('multilingue', 1), ('fonctionnant', 1), ('principe', 1), ('.', 1), ('Aimez-vous', 1), ("l'encyclopédie", 1), ('wikipedia', 1), ('?', 1)]This function returns a two-dimensional array in which we find each value of the corpus with its frequency of distribution. For example, the word wiki is placed twice in the text.
Stemmatization
Now it would be interesting to group together the words having the same synthaxic root, for that we will use the stemmatization function of NLTK: stem (). Good news again there is a function for the French FrenchStemmer () ! we will of course use it here:
example_words = ["donner","don","donne","donnera","dons","test"]
stemmer = FrenchStemmer()
for w in example_words:
print(stemmer.stem(w))
don
don
don
don
don
testThe stemmatization function has found the roots of the word “donation”. Honestly it does not always work as well unfortunately, but this function can nevertheless be useful for a first clearing.
Conclusion
The objective of this article being to show the basic functionalities of NLTK we have not gone into detail. This library is rich, very rich even but requires a lot of adjustment if you want to create powerful NLP-based functions. The differences with SpaCy ? in fact there are a lot of them, the philosophy of these two libraries is totally different (object vs traditional approach for NLTK for example) … in fact I think that we should rather see these two libraries as complementary, each bringing to the other its own shortcomings.