

Qu’est-ce que le Profiling ?
Avant de rentrer dans le vif du sujet nous devons préciser ce qu’est le profiling. Regardons la définition wikipédia : « Le profiling est le processus qui consiste à récolter les données dans les différentes sources de données existantes (bases de données, fichiers,…) et à collecter des statistiques et des informations sur ces données. » Ouch ! Disons simplement que le profiling c’est l’analyse des données à partir des données elle mêmes.
Bref, l’idée est simple: vous avez des données – dont vous ne savez que peu ou pas de choses – et vous voulez les faire parler au moins d’un point de vue contenu. Bien sur vous avez (ou pas d’ailleurs) une bonne documentation sur le sujet. Mais celle-ci est-elle à jour ? pas sur ! de toute façon pas question de lui faire confiance, celle-ci est probablement obsolète.
Vous allez donc devoir auditer vos données ! et la première étape de cet audit c’est le profiling.
Mais que va faire le profiling ? et bien scanner toutes les données et ce sans apriori de structure (cad sans se fier aux structures de données documentées). En effet pas question de cibler des problèmes déjà connu, ça serait bien trop facile ! Non le profiling se doit d’être sans idées préconçues.
Le Profiling est un état des lieux objectif de vos données telles qu’elles sont réellement dans vos systèmes.
Pas question donc de faire du SQL ! vous ne devez rien configurer dans cette étape c’est une approche qui vous contraint à garder votre objectivité sur cette étape. Vous devez donc vous outiller, et c’est ce que je vais faire dans la seconde partie de cet article en utilisant Informatica Data Quality 10.2
Et bien profilons nos données
Et profilons-les sur une jeu de données sur un fichier contenant des personnes physiques. Lançons pour cela Informatica Analyst (l’outil client web d’Informatica Data Quality) pour lancer le profiling.
Après avoir choisi l’option New> Profile>
Vous pouvez choisir la source de données à analyser (profiler) :
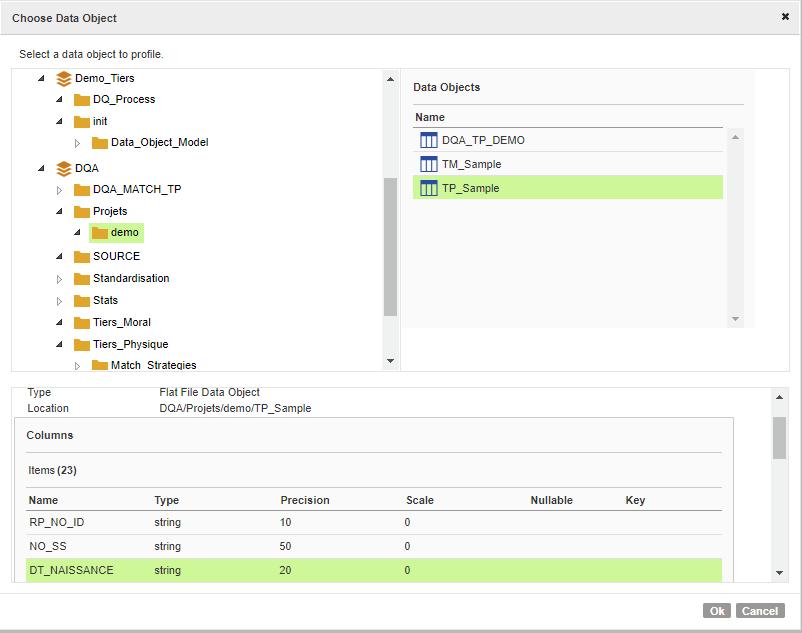
Suivez les instructions et en quelques clics de souris votre fichier va être analysé.
Analysons les résultats
Résultat global
Le résultat ne se fait pas attendre et est affiché directement dans l’Analyst, voici l’écran de synthèse fournit :

Le cadre de gauche propose de voir les champs filtrés par :
- Columns and Rules : pour voir tous les champs
- Columns ; seulement les colonnes
- Rules: Seulement les règles appliquées aux données. La solution permet en effet de créer des règles qui combinerons les données du jeu de données pour présenter des résultats composites.
- « 100% Null » : Seulement les colonnes non renseignées
- « 100% Distinct » : seulement les colonnes qui n’ont que des valeurs distinctes
- « 100% Constant »: seulement les colonnes qui ont des valeurs constantes
- Conflicting Data Types : seulement les colonnes dont le résultat d’analyse en matière de typage ne correspond pas à celui documenté.
- Inferred DataDomains : Les colonnes pour lesquelles Informatica Data Quality a pu déterminer des types de données plus pertinent (par exemple détection d ’emails, numéro de téléphone, etc.)
- Pattern/Freq. outliers; Dans le monde des statistiques ou du Machine learning les outliers sont les valeurs qui sortent du lot. par exemple il peut s’agir de valeurs qui « perturbent une distribution gaussienne. Bref, il s’agit peut être de valeurs à ne pas prendre en compte. Informatica Data quality détecte automatiquement ces valeurs par rapport à un pattern ou via leur fréquence de distribution.
Le cadre de droite permet lui de visualiser les colonnes/champs avec des informations automatiquement récoltées/calculées par l’outil :

- Le pourcentage ;
- de valeurs Nulles (Rouge)
- de valeurs distinctes (Vert)
- de valeurs non-distinctes (doublons) (Noir)
- Les valeurs minimum et maximum
- La répartition par pattern
- La longueur (min/max)
- Les types de données constaté
- Les data domains (cad les types avancés : exemple : mail, numéro de tel, etc.)
Quelques premières conclusion en un coup d’oeil :
- Les champs BIRTH_DATE, DEATH_DATE, MOBILE_PHONE ne sont pas toujours renseignés
- Le champ email n’a que 90% d’email dedans
- Les données ne sont que française (NATIONNALITE toujours égal à FR)
- On a des doublons de téléphone (3 en tout)
- etc.
Résultat par colonne/champ
Maintenant il s’agit d’un écran interactif, cliquez juste sur la colonne pour aller dans le détail. Zoomons sur la colonne BIRTH_DATE:
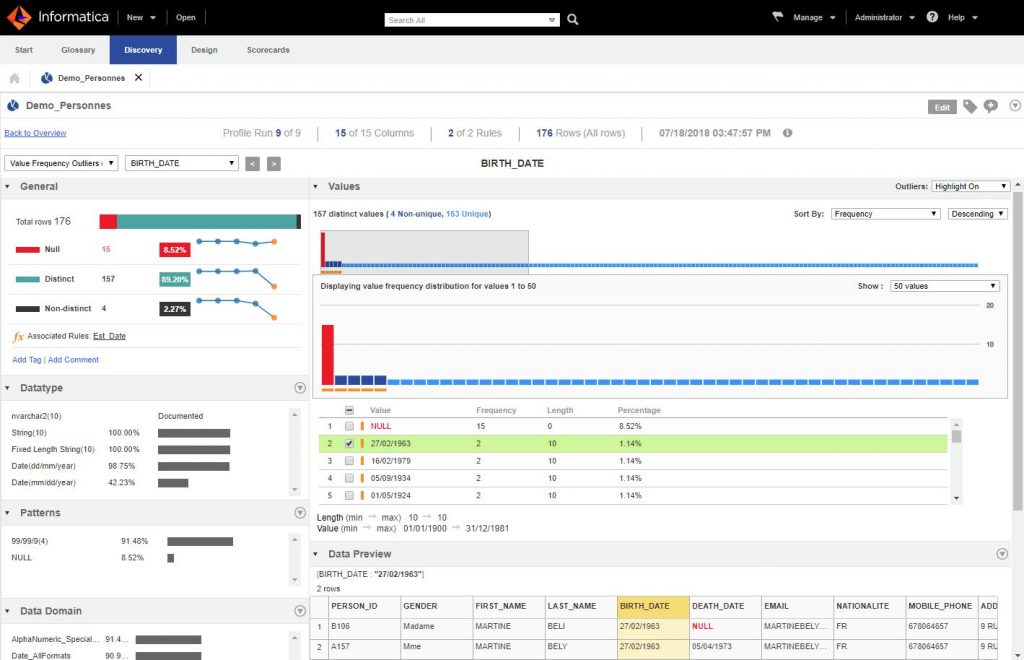
L’écran est bien fourni et regorge d’informations diverses.
Tout d’abord le panneau à gauche propose pour cette colonne/champ :
- Le nombre de valeurs nulles (complétude)
- La quantité valeurs distinctes
- Le nombre de valeurs en double (non distinctes)
Mais si vous regardez bien l’écran propose même pour chacun de ces indicateurs leur évolution dans le temps. En effet si vous lancez à plusieurs reprise le Profiling vous pourrez comparer vos résultats avec les précédents. Pratique si vous avez des données en streaming par exemple !
Dessous vous avez plusieurs cadres :
- Datatypes : qui propose les types de données constaté dans cette colonne
- Patterns : qui vous montre quels sont les patterns (la structure de la donnée même)
- Data Domains : les types de données avancés (email, dates, numéro de teléphone, etc.)
Dans le cadre Value de droite vous avez un graphique qui vous montre la distribution des valeurs pour cette colonne. Les outiers (valeurs hors norme) sont marquées par un carré orange. Vous pouvez vous balader sur ce graphe mais aussi et surtout consulter les valeurs et faire du drilldown à tout moment sur telle(s) ou telle(s) valeur(s). D’ailleurs vous pouvez faire du drilldown sur tout type de constat (sur les patterns, datatypes, etc.).
On constate par exemple ici que les valeurs sont quasiment toutes distinctes … exceptées 4 dates en doubles ! tiens il serait peut être interressant de voir ce qu’il y a derrière ces dates. Si on fait un drilldown sur la date 27/02/1963 (Cf. écran ci-dessus) on vérifie en quelque clic qu’un doublon se cache derrière (Mme Beli vs Mme Bely).
Suites et conclusion
Bien sur le profiling et l’analyse des données ne s’arrete pas ici. En fait c’est plutot le contraire : ce n’est que le point de départ indispensable d’une bonne analyse de données. L’avantage de cette première étape est qu’elle ne produit aucun effort … pour l’utilisateur 😉 il suffit de se laisser guider et de constater les résultats.
L’étape suivante va sans doute demander un peu plus d’effort car bien souvent :
- Vous allez devoir créer et appliquer des règles métier.
- Il faudra aussi croiser les données de plusieurs sources différentes (hétérogènes). Là aussi vous aurez besoin d’un outil vous permettant de le faire simplement.
Heureusement certains outils tels que Informatica Data Quality vous propose un éditeur de règles et vous permettent d’appliquer directement ces règles dans l’analyse que nous venons de voir. Il propose aussi la possibilité de croiser les informations cross-datasources ce qui va très rapidement s’avérer indispensable. Mais ces possibilités ne font pas partie du présent article aussi je vous propose de la passer en revue lors d’un autre billet.
Pour conclure, le profiling est une première étape indispensable de tout projet de données. C’est d’autant plus un atout qu’il va vous fournir bon nombre d’informations sans efforts et de manière totalement objective !
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
One Reply to “Le Profiling”