

Le Feature Scaling
Mon dieu, mais qu’est-ce encore que le Feature Scaling ? un nouvel anglicisme barbare ? un nouvel effet de bord marketing ? Ou alors se cache quelque chose de réellement pertinent derrière ? Pour tout dire, le Feature Scaling est une étape nécessaire voire indispensable de remise à niveau de caractéristiques de notre modèle de Machine Learning. Pourquoi ? et bien tout simplement car derrière chaque algorithme se cache des formules mathématiques. Et ces formules mathématiques n’apprécient guère les variations d’échelle de valeurs entre chaque caractéristiques. Et ça c’est tout particulièrement vrai en ce qui concerne la descente de gradient !
Si vous ne faites rien vous allez observer des lenteurs d’apprentissage et des performances amoindries.
Prenons un exemple. Imaginez que vous travaillez sur une modélisation autour de données immobilières. Vous aurez des caractéristiques du type : prix, surface, nombre de pièces, etc. Bien sur les échelles de valeurs de ces données sont totalement différentes selon les caractéristiques. Néanmoins vous allez devoir les traiter via le même algorithme. C’est là que le bas blesse ! votre algorithme va en effet devoir mixer des prix de [0 … 100000]€, des surfaces de [0 … 300] m2, des nombres de pièces allant de [1 .. 10] pièces. La mise à l’échelle consiste donc à mettre au même niveaux ces données.
Heureusement Scikit-Learn va encore une fois nous mâcher le travail, mais avant d’utiliser tel ou tel technique il faut comprendre comment chacune d’elle fonctionne.
Préparation des tests
Avant toute chose nous allons créer des jeux de données aléatoires ainsi que quelques fonctions de graphes qui nous aideront à mieux comprendre les effets des différentes techniques utilisées (ci-dessus).
Voici le code Python :
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import MaxAbsScaler
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
def plotDistribGraph(pdf):
fig, a = plt.subplots(ncols=1, figsize=(16, 5))
a.set_title("Distributions")
for col in pdf.columns:
sns.kdeplot(pdf[col], ax=a)
plt.show()
def plotGraph(pdf, pscaled_df):
fig, (a, b) = plt.subplots(ncols=2, figsize=(16, 5))
a.set_title("Avant mise à l'echelle")
for col in pdf.columns:
sns.kdeplot(pdf[col], ax=a)
b.set_title("Apres mise à l'echelle")
for col in pdf.columns:
sns.kdeplot(pscaled_df[col], ax=b)
plt.show()
def plotGraphAll(pdf, pscaled1, pscaled2, pscaled3):
fig, (a, b, c, d) = plt.subplots(ncols=4, figsize=(16, 5))
a.set_title("Avant mise à l'echelle")
for col in pdf.columns:
sns.kdeplot(pdf[col], ax=a)
b.set_title("RobustScaler")
for col in pscaled1.columns:
sns.kdeplot(pscaled1[col], ax=b)
c.set_title("MinMaxScaler")
for col in pscaled2.columns:
sns.kdeplot(pscaled2[col], ax=c)
d.set_title("StandardScaler")
for col in pscaled3.columns:
sns.kdeplot(pscaled3[col], ax=d)
plt.show()
np.random.seed(1)
NBROWS = 5000
df = pd.DataFrame({
'A': np.random.normal(0, 2, NBROWS),
'B': np.random.normal(5, 3, NBROWS),
'C': np.random.normal(-5, 5, NBROWS),
'D': np.random.chisquare(8, NBROWS),
'E': np.random.beta(8, 2, NBROWS) * 40,
'F': np.random.normal(5, 3, NBROWS)
}
Dans ce code, hormis les fonctions de traces nous créons 6 jeux de données dans un seul DataFrame (Pandas).
Regardons déjà à quoi ressemblent nos jeux de données :
plotDistribGraph(df)
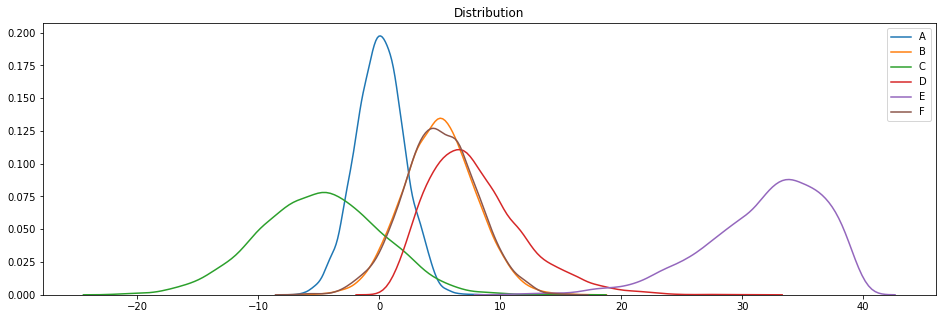
Ces jeux de données sont basées sur des distributions gaussienne (A, B, C et F), X2 (D) et beta (E) (grâce aux fonctions Numpy np.random).
Ce code est réutilisable volontairement afin que vous puissiez faire varier les jeux de données et tester les techniques présentées.
Les techniques
En gros Scikit-Learn (sklearn.preprocessing) fournit plusieurs techniques de mise à l’échelle, nous allons en passer en revue 4:
- MaxAbsScaler
- MinMaxScaler
- StandardScaler
- RobustScaler
MaxAbsScaler()
Cette technique de mise à l’échelle est utile dés lors que la distribution de valeurs est éparses et que vous avez pas mal d’outiers. En effet les autres techniques auront tendance à effacer l’impact des outliers ce qui parfois est gênant. Elle est donc intéressante :
- Car robuste à de très petites déviations standard
- Elle préserve les entrées nulles sur une répartition de données éparses
scaler = MaxAbsScaler() keepCols = ['A', 'B', 'C'] scaled_df = scaler.fit_transform(df[keepCols]) scaled_df = pd.DataFrame(scaled_df, columns=keepCols) plotGraph(df[keepCols], scaled_df)
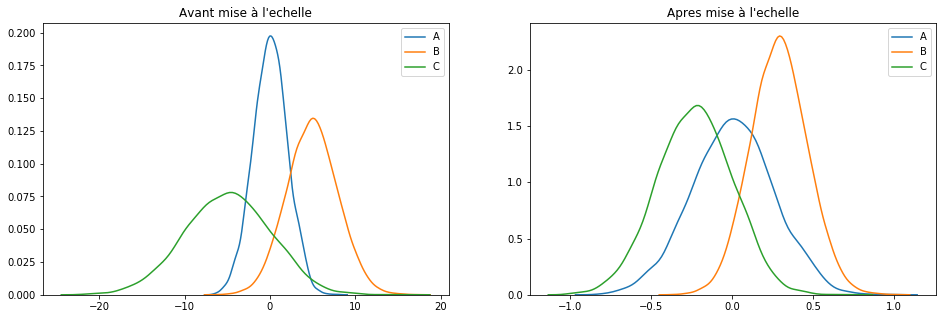
Pour résumer : cette technique se contente de rassembler les valeurs sur une plage de [-1, 1].
MinMaxScaler()
Cette technique transforme les caractéristiques (xi) en adaptant chacune sur une plage donnée (par défaut [-1 .. 1]). Il est possible de changer cette plage via les parametres feature_range=(min, max). Pour faire simple voici la formule de transformation de chaque caractéristique :
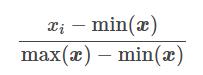
Voyons là à l’œuvre :
scaler = MinMaxScaler() keepCols = ['A', 'B', 'C'] scaled_df = scaler.fit_transform(df[keepCols]) scaled_df = pd.DataFrame(scaled_df, columns=keepCols) plotGraph(df[keepCols], scaled_df)
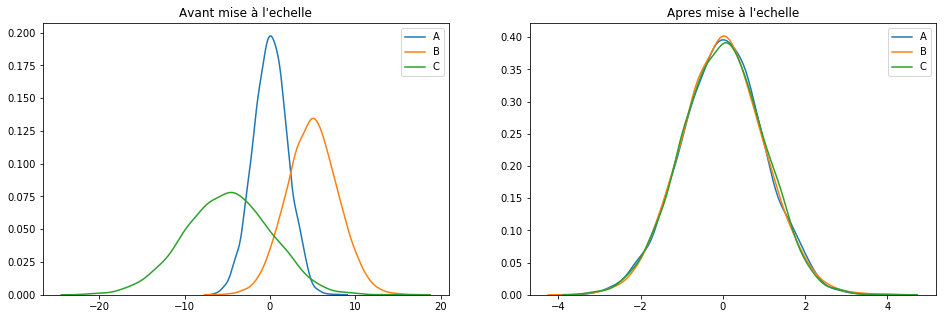
Si cette technique est probablement la plus connue elle fonctionne surtout bien pour les cas où la distribution n’est pas gaussienne ou alors quand l'[itg-glossary href= »http://www.datacorner.fr/glossary/ecart-type/ » glossary-id= »15640″]Ecart-Type[/itg-glossary] est faible. Néanmoins et contrairement à la technique MaxAbsScaler(), MinMaxScaler() est sensible aux outliers.dans ce cas on bascule vite sur une autre technique : RobustScaler().
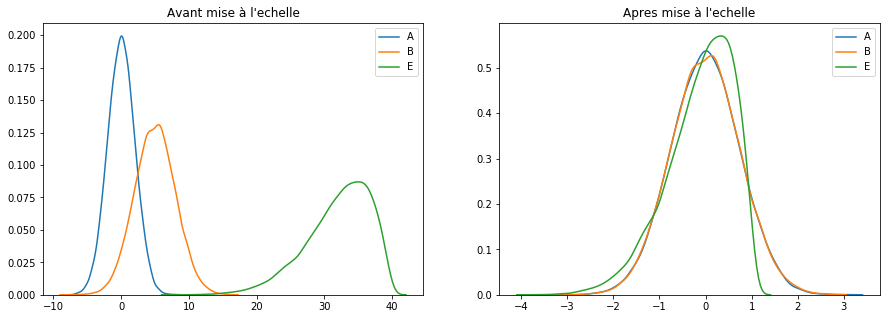
RobustScaler()
La technique RobustScaler() utilise utilise le même principe de mise à l’échelle que MinMaxScaler(). Néanmoins, elle utilise l’intervalle interquartile au lieu du min-max, ce qui la rend plus fiable vis à vis des outliers. Voici la formule de re-travail des caractéristiques :
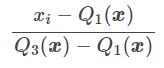
Q1(x) : 1er quantile / 25%
Q3(x) : 3ème quantile / 75%
Voyons là à l’œuvre :
scaler = RobustScaler() keepCols = ['A', 'B', 'E'] scaled_df = scaler.fit_transform(df[keepCols]) scaled_df = pd.DataFrame(scaled_df, columns=keepCols) plotGraph(df[keepCols], scaled_df)
StandardScaler()
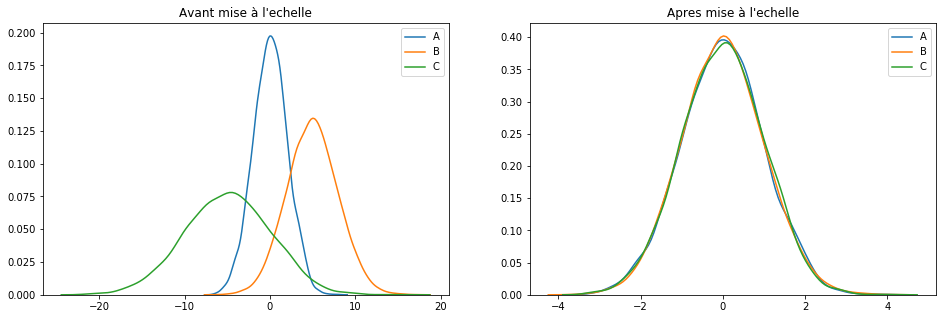
Nous finirons notre petit tour (non exhaustif) des techniques de mise à l’échelle par sans doute la moins risquée : StandardScaler().
Cette technique part du principe que les données sont normalement distribuées. La fonction va recalculer chaque caractéristiques (Cf. formule ci-dessous) afin que les données soient centré autour de 0 et avec un [itg-glossary href= »http://www.datacorner.fr/glossary/ecart-type/ » glossary-id= »15640″]Ecart-Type[/itg-glossary] de 1.
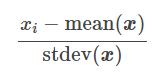
mean(x) : Moyenne
stdev(x) : « Standard Deviation » en Anglais signifie Ecart-Type
Voyons là à l’œuvre :
scaler = StandardScaler() keepCols = ['A', 'B', 'C'] scaled_df = scaler.fit_transform(df[keepCols]) scaled_df = pd.DataFrame(scaled_df, columns=keepCols) plotGraph(df[keepCols], scaled_df)
A retenir
Résumons simplement les techniques de Feature Scaling que nous venons de rencontrer:
- MaxAbsScaler : a utiliser quand les données ne sont pas en répartition normale. Tient compte des outliers.
- MinMaxScaler : calibre les données sur une plage de valeurs.
- StandardScaler : recalibre les données pour des répartitions normales.
- RobustScaler : identique à Min-Max mais utilise l’intervalle interquartile au lieu des valeurs Min et Max.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
2 Replies to “Machine Learning : La mise à l’echelle”