

Le découpage du jeu de données dans un projet de Machine Learning est une étape très importante qu’il ne faut pas négliger faute de quoi vous risquer de sur évaluer votre modèle (over-fitting) ou tout simplement le contraire (under fitting). En effet par nature un modèle va coller (mais pas trop) à ses données d’entrainement.
Cett étape est donc une étape préalable mais aussi une étape d’optimisation qu’il ne faut pas laisser de coté. Nous allons voir dans cet article comment gérer ses jeux de données avec Python et Orange.
Données d’entraînement vs. données de test
Comme nous l’avons vu dans la démarche d’un projet de Machine Learning il est indispensable de disposer de deux jeux de données minimum : l’un pour l’entrainement du modèle et l’autre pour sa validation. Or bien souvent vous récupérer des données en bloc !
Qu’à cela ne tienne, il suffit de découper votre jeu de données en deux (disons 30% pour les données de test que l’on met de coté et le reste pour l’entrainement) !

Mais dans ce cas comment découper vos données tout en conservant une certaine cohérence et surtout représentativité ? Difficile, voire impossible en fait surtout dés lors que votre jeu de données atteint une quantité importante. Nous allons voir comment palier à ce problème au travers de plusieurs techniques.
Découper ses données
Python Scikit-Learn propose une fonction très pratique pour découper les jeux de données : train_test_split. Ici nous demandons une répartition du jeu de données 33% pour les données de test et le reste pour l’entraînement :
import pandas as pd
from sklearn.model_selection import train_test_split
train = pd.read_csv("../datasources/titanic/train.csv")
X = train.drop(['Survived', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked' ], axis=1)
X['Pclass'] = X['Pclass'].fillna(5)
X['Age'] = X['Age'].fillna(X['Age'].mean())
X['Fare'] = X['Fare'].fillna(X['Fare'].mean())
y = train['Survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
print ("Train=" + str(X_train.shape) + ", Test=" + str(X_test.shape))
Train=(596, 6), Test=(295, 6)La fonction train_test_split nous renvoit nos jeux de données (Observation=X, résultat=y) découpées en jeux d’entraînement et test. en ajustant les paramètres random_state et shuffle on peut même régler le degré de choix (aléatoire) de distribution dans l’un ou l’autre jeu de données.
Si vous utilisez Orange (outil de Data-Science gratuit et Open-Source), vous n’aurez qu’à utiliser le widget Data Sampler :
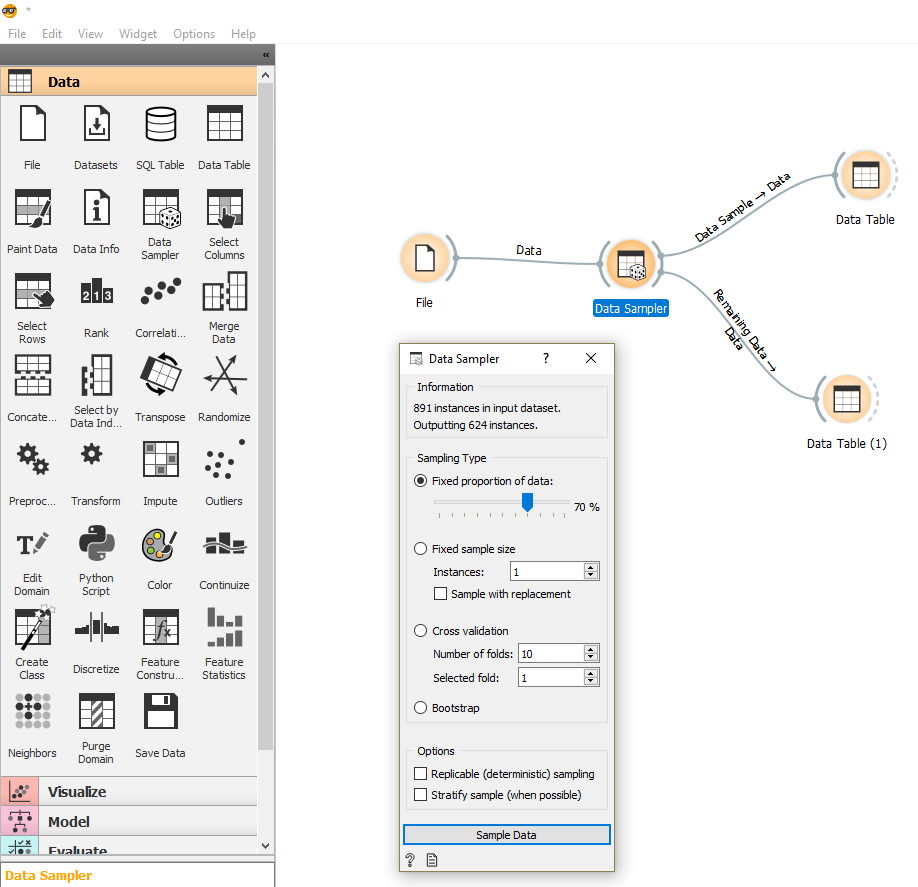
Découper encore
Si ce premier découpage est indispensable voir vital, il ne suffit malheureusement pas toujours. Afin d’optimiser le réglage de son modèle nous allons lors de la phase d’entraînement découper encore le jeu d’entraînement pour s’assurer à minima que nous ne collons pas trop aux données utilisées.
Pour optimiser l’entraînement et vérifier la cohérence du modèle nous allons découper plusieurs fois notre jeux de données d’entraînement et l’entrainer à chaque fois (via itération) sur une partie. On pourra alors voir si le scoring est cohérent sur tous les découpages réalisés:
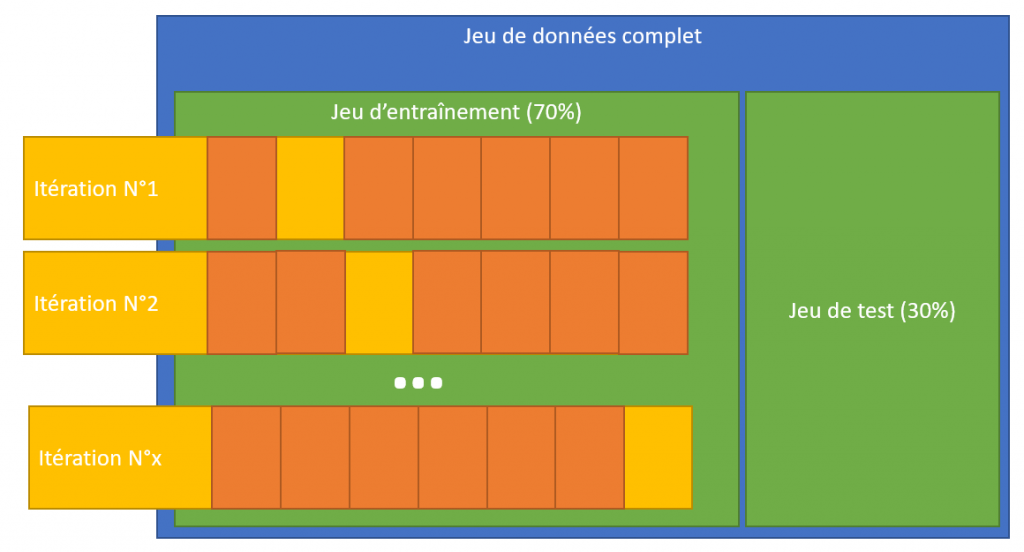
On peut directement effectuer cette cross-validation avec l’algorithme (en utilisant l’hyperparametre cv). Dans le cas ci-dessous on découpe en deux étapes :
clf = svm.SVC(kernel='linear', C=1) score = cross_val_score(clf,X, y, cv=2)
array([0.66591928, 0.73033708])On peut aussi utiliser l’objet KFold de sklearn. Dans l’exemple ci-dessous on effectue un découpage en 4 :
kf = KFold(n_splits=4, random_state=None, shuffle=False)
kf.split(X)
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index.shape, "TEST:", test_index.shape , str("\n"))
print("TRAIN:", train_index, "\n\nTEST:", test_index , str("\n"))
Il suffit ensuite de passer le découpage réalisé à l’algorithme pour voir le résultat :
score = cross_val_score(clf,X, y, cv=kf)
array([0.6367713 , 0.68609865, 0.71748879, 0.72522523])Comme d’habitude retrouvez les sources de cet article sur Github.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
One Reply to “Découper ses données”